8. Путь пакета¶
Ну что же, кажется мы добрались до того момента, когда можно взглянуть на длинную и нелегкую жизнь, что предстоит прожить сигналу, несущему пакету.
Одночиповое устройство¶
Сначала рассмотрим пример попроще с single-chip shared buffer коробкой.
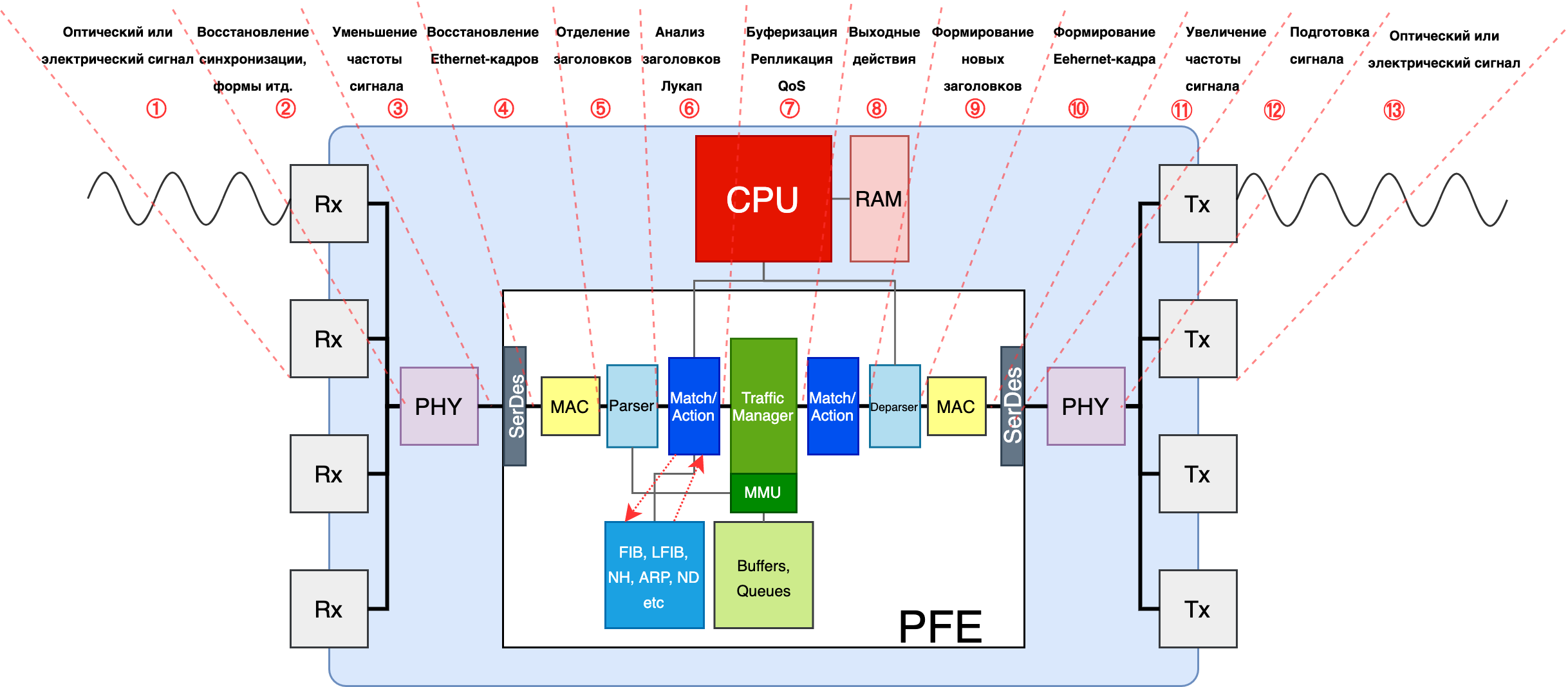
Оптический или электрический сигнал приходит в интерфейс.
Далее он попадает на чип PHY, который его усиливает, восстанавливает форму сигнала и синхронизацию (3R - Re-amplification, Re-shaping, Re-timing)
Из PHY сигнал по медным контактам бежит на SerDes чипа коммутации. Частота электрического сигнала здесь всё ещё десятки ГГц (для скоростей 10 Гб/с и выше). SerDes, понижает частоту (за счёт демодуляции NRZ, PAM4) до удобоваримой для чипа и передаёт его на модуль MAC.
Далее этот Ethernet кадр ещё со всем заголовками отправляется на Parser. Тот отделяет управляющие заголовки от тела. Тело он складывает во встроенный буфер. Причём оно расчленяется на ячейки, чтобы плотно упаковаться в доступные сегменты памяти. Управляющими являются те заголовки, на основе которых применяется решение о маршрутизации пакета - Ethernet, MPLS, IP, TCP/UDP (для ACL и LAG/ECMP).
Пока тело хранится в буфере, набор заголовков передаётся на анализ в блок Match-Action.
Сначала изучается Dst MAC. FE делает лукап в MAC-таблице (например, в памяти CAM). Если DMAC совпадает с MAC’ом самого узла, то кадр передаётся на обработку по конвейеру дальше. Если нет, то кадр коммутируется согласно таблице и на этом всё.
- Значение TTL/Hop Limit.
- Адрес назначения (IP, MPLS-метка итд.)
- Приоритет (DSCP, EXP итд.)
- Возможно понадобятся и другие поля, такие как адрес источника, информация о вложенных данных (протокол, порт, приложение)
Пока тело всё ещё прохлаждается во внутричиповом буфере, происходит принятие десятков решений о его судьбе:
Уменьшение TTL/Hop Limit на 1 и проверка, не равен ли он 0. Если равен - то запрос на CPU для генерации ICMP TTL Expired in Transit.
Проверка по ACL - можно ли вообще передавать этот трафик.
Принятие решения о назначении пакета на основе Dst IP или верхней MPLS-метки.
Входной тракт чипа коммутации здесь делает лукап в FIB в попытке найти маршрут, соответствующий данному IP-адресу (или в LFIB, для поиска LSP). Будь то поиск в TCAM или запрос в блок алгоритмического поиска результатом будет указатель в RAM, где хранится искомая запись с набором инструкций.
Чип из RAM получает этот набор инструкций: выходной интерфейс, NextHop, инкапсуляции, выходной стек меток итд. При необходимости осуществляется рекурсивный лукап. В большинстве случаев чип коммутации выясняет на этом шаге MAC-адрес Next-Hop’а из таблицы соседей (Adjacenсies Tables/ND Tables).
Если некстхопов несколько, а соответственно и несколько комбинаций (выходной интерфейс, инкапсуляция), то чип считает хэш от полей заголовков для определения в какой из членов LAG или ECMP послать этот пакет.
Если адрес назначения локальный, то или парсится следующий заголовок (как это и было выше с Ethernet), или принимаются какие-то меры аппаратные (BFD, например) или пакет передаётся на CPU (BGP, OSFP итд.)
Преобразование приоритета из заголовков пакета во внутреннюю CoS-метку, в соответствии с которой пакет будет обрабатываться в пределах данного узла. Может навешиваться приоритет обработки в очередях и приоритет отбрасывания пакета.
Всё это станет метаданными и будет помещено во временный заголовок, сопровождающий пакет до выходного тракта:
- Выходной интерфейс
- Приоритет
- TTL
- Next Hop/стек меток
- Другое
Для BUM трафика модуль Match-Action определяет список выходных интерфейсов, но не создаёт реплики пакета - эта информация добавляется в метаданные.
Note
Важно понимать, что до завершения этого шага никаких решений о перегрузках, отбрасывании пакетов и очередях не принимается - тело пакета в любом случае сохраняется в буфере на время обработки заголовков и поиска выходного интерфейса
Далее из модуля TM метаданные о пакете кочуют в Egress Match-Action, где над ними производятся дополнительные экзекуции, в виде, например, выходных ACL.
Deparser получает метаданные, формирует из них стек заголовков. В частности здесь он преобразует внутренний приоритет в значения приоритетов IP/MPLS/Ethernet, записывает правильный TTL, пересчитывает контрольные суммы итд. Так же Deparser извлекает бренное тело из буфера, склеивает его с новыми заголовками, и передаёт блоку MAC.
И потом всё раскручивается в другую сторону: MAC добавляет IFG, преамбулу, считает новую контрольную сумму кадра и добавляет трейлер FCS.
SerDes теперь повышает частоту и отправляет сигнал в медные дорожки.
PHY готовит сигнал для передачи в среду (медь, оптика, радио).
С порта счастливый пакет уходит в своё короткое (или не очень) плавание до следующей пристани.
Note
Это, несомненно очень упрощённый пример обработки трафика. Более того, он рассматривает частный пример реализации. Фактически чип MAC может стоять отдельно от чипа коммутации, или наоборот PHY быть его частью. PHY может самостоятельно понижать частоту, и тогда не нужны SerDes. Репликация BUM может происходить на TM, а может на выходном тракте. Дорожки, в случае Silicon Photonics будут не электрическими, а оптическими. И много прочих нюансов
Если заменить Shallow Buffer на Deep Buffer, то в случае перегрузок тело пакета может сохраняться на внешнюю память.
Многочиповое устройство¶
Нередки случаи, когда в одну коробку ставится два-три и больше чипов для увеличения производительности.
Тогда входному чипу коммутации нужно ещё определить и выходной чип во время лукапа и указать его в метаданных. Поскольку обработка будет происходить дважды на двух разных чипах, естественно, тело пакета передаётся между ними и буферизируется дважды. Тут возможны разные архитектуры памяти, но VOQ одна из наиболее удобных - буфер выходного чипа в этом случае используется только как FIFO, а вся нагрузка по обеспечению QOS ложится на входной TM.
Модульное устройство¶
Значительно усложняется картина в случае шассийных коробок. Добавляется VOQ на входном чипе, фабрика, обработка на выходном, арбитраж с пиггибэком.
Для шассийных коробок процесс изменится так.
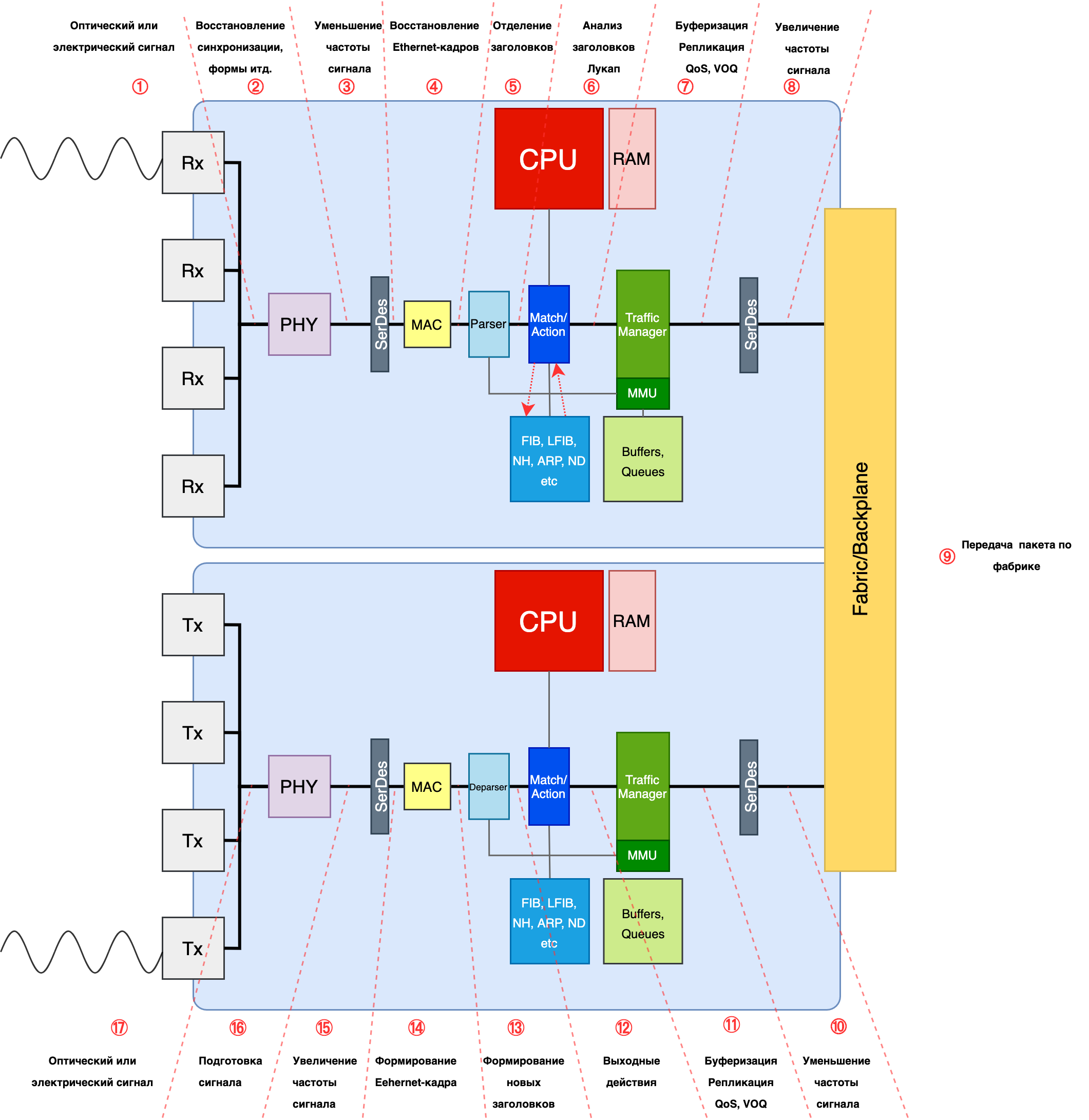
То есть чип из RAM должен извлечь следующий набор инструкций: выходной чип, выходной интерфейс, NextHop, инкапсуляции, выходной стек меток итд.
И следующие метаданные будут привязаны к пакету:
- Выходной чип
- Выходной интерфейс
- Приоритет
- TTL
- Next Hop/стек меток
- Другое
С BUM трафиком ситуация тоже не меняется - модуль Match-Action определяет список выходных чипов и интерфейсов и вносит это в метаданные.
У TM тоже работы прибавляется.
В подавляющем большинстве случаев на линейных картах модульных шасси будет VOQ на входе. То есть для каждого возможного выходного интерфейса (по сути для всех существующих) будет создана очередь на выходном чипе. TM, уже обладая информацией о том, куда пакет должен быть направлен, помещает его в очередь, отвечающую за данный выходной интерфейс. И соответственно поступает с ним так, как того требуют приоритет пакета, условия перегрузок, настроек QoS на данном конкретном порту.
Если используется арбитр (а он используется, бьюсь об заклад), то TM должен ещё и на отправку пакета получить разрешение от выходного чипа, чтобы быть уверенным, что этот пакет не будет отброшен из-за конгестии на выходном порту.
Ну и кроме всего прочего TM должен выполнить репликацию BUM-пакетов. Но не во все порты, за которыми есть получатели этого трафика, а только по числу выходных чипов, за которыми они есть. Что и логично, чтобы не забивать фабрику.
Ну а дальше у пакета недолгий путь через фабрику коммутации. В этом путешествии ему не обойтись без верного спутника - временного заголовка с его метаданными.
Пакет обычно шинкуется на ячейки одинакового размера, каждой из них приклеивается этот метазаголовок и порядковый номер, и отправляется на фабрику.
На выходной плате ячейки обратно спекаются в один пакет и попадают на TM. В целом в зависимости от реализации здесь чего с ним только может не происходить, но базовый минимум - это просто FIFO очередь (потому что QoS отработал на входной плате) и репликация BUM-пакетов по числу портов-подписчиков.
Следующим пристанищем пакета становится выходной чип коммутации. Здесь могут приниматься ещё какие-то решения о передаче, например, выходные ACL.
Ну а дальше Deparser → MAC → SerDEs → PHY → интерфейс → среда
Локальные пакеты¶
Бо́льшая часть локальных пакетов обрабатываются на ЦПУ.
Напомню, что локальные - это те, которые были созданы на данном узле или которые предназначены именно ему (юникастовые), которые предназначены всем/многим (броадкастовые или мультикастовые). К ним относятся пакеты протоколов Control Plane (BGP, OSPF, LDP, LLDP итд), пакеты протоколов управления (telnet, SSH, SNMP, NetConf итд), пакеты ICMP.
К ним же стоит отнести транзитные протоколы, требующие обработки Control Plane’ом узла (TTL Expired, Router Alert).
Входящие¶
Вплоть до блока Match-Action с ними происходит всё то же самое, что и с транзитными. Далее чип коммутации, обратившись в таблицу MAC-адресов , видит, что DMAC - это MAC-адрес локального устройства, заглядывает в EtherType. Если это какой-нибудь BPDU или ISIS PDU, то пакет сразу передаётся нужному протоколу.
Если IP - передаёт его модулю IP, который, заглядывая в FIB, видит, что и Dst IP тоже локальный - значит нужно посмотреть в поле Protocol заголовка IPv4 (или Next Header IPv6).
Определяется протокол, принимается решение о том, какому модулю дальше передать пакет - BFD, OSPF, TCP, UDP итд. И так пакет разворачивается до конца, пока не будет найдено приложение назначения.
Если данный пакет принёс информацию об изменении топологии (например, новый OSPF, LSA), Control Plane должен обновить Soft Tables (RAM), а затем изменения спускаются в Hard Tables (RAM/CAM/TCAM+RAM).
Если пакет требует ответа, то устройство должно его сформировать и отправить назад изначальному источнику (например, TCP Ack на пришедший BGP Update) или передать куда-то дальше (например, OSPF LSA или RSVP Resv).
Исходящие¶
Исходящие протокольные пакеты формируются на ЦПУ - он заполняет все поля всех заголовков на основе Soft Tables и далее, в зависимости от реализации, спускает его на Ingress или Egress FE.
Attention
Из-за того, что пакет сформирован на процессоре, зачастую он не попадает под интерфейсные политики. Архитектурно многие операции, выполняющиеся на FE, требуют того, чтобы FE производил Lookup и формировал заголовки.Отсюда могут быть любопытные и неочевидные следствия, например, их не получится отловить ACL, вы можете не увидеть их в зазеркалированном трафике, они не будут учитываться при ограничении скорости. Но это зависит от вендора и оборудования.Однако политики, работающие с очередями на CPU их, конечно, увидят.
Есть некоторые протоколы Control Plane, которые всё-таки обрабатываются в железе. Ярким примером может служить BFD. Его таймеры выкручиваются вплоть до 1 мс. CPU, как мы помним, штука гибкая, но неповоротливая, и пока BFD-пакет пройдёт по всему тракту и развернётся до заголовка BFD, пока до процессора дойдёт прерывание, пока тот на него переключится, прочитает пакет, сгенерирует новый, вышлет его, пройдут десятки и сотни миллисекунд - глядь, а BFD-то уже развалился.
Поэтому пакеты BFD в большинстве случаев разбираются на чипе, на нём же и готовится ответ. И только сама сессия устанавливается через CPU.
..note:: Большие в этом вопросе пошли ещё дальше, перенеся на железо наиболее рутинные операции. Так, например, Juniper ввёл PPM - Periodic Packet Management, который разделяет функции Control Plane некоторых протоколов между управляющим модулем и интерфейсным:
- Bidirectional Forwarding Detection (BFD)
- Connectivity Fault Management (CFM)
- Link Aggregation Control Protocol (LACP)
- Link Fault Management (LFM)
- Multiprotocol Label Switching (MPLS)
- Real-time Performance Monitoring (RPM)
- Spanning Tree Protocol (STP)
- Synchronous Ethernet (SYNCE)
- Virtual Router Redundancy Protocol (VRRP)
Note
История выше отсылает нас к длинным пингам. Иногда инженер проверяет RTT своей сети путём пинга с одного маршрутизатора на другой. Видит вариацию в десятки и сотни мс и, начиная переживать, открывает запросы вендору. Пугаться тут нечего. Обычно ICMP обрабатывается на CPU. И именно занятостью процессора определяется время ответа. При этом корреляция с реальным RTT сети практически нулевая, потому что транзитный трафик на CPU не обрабатывается.Некоторые современные сетевые устройства могут обрабатывать ICMP-запросы и формировать ICMP-ответы на чипе (NP, ASIC, FPGA), минуя долгий путь до CPU. И вот в этом случае циферки в ping будут адекватны реальности. Но я бы всё же на это не полагался