Чипы для датацентровых коммутаторов¶
Чтобы упростить себе жизнь, я продолжу далее разговор только об ASIC’ах под датацентровые коммутаторы, не пытаясь обнять Джабба Хатта.
Сегодня конкуренцию ему пытаются составить Mellanox со своими собственными чипами Spectrum (ныне уже Nvidia), Innovium Teralynx, Barefoot Tophino (ныне Intel). Своим появлением эти компании раскачивают рынок и провоцируют среди вендоров тренд на переход от внутренних разработок к готовым чипам их производства.
Мы в конце книги взглянем на их модельные ряды, но пока давайте обсудим, чем же чипы характеризуются и могут отличаться друг от друга.
А для этого надо понять, какие они задачи решают.
В датацентровых сетях есть три основных типа устройств:
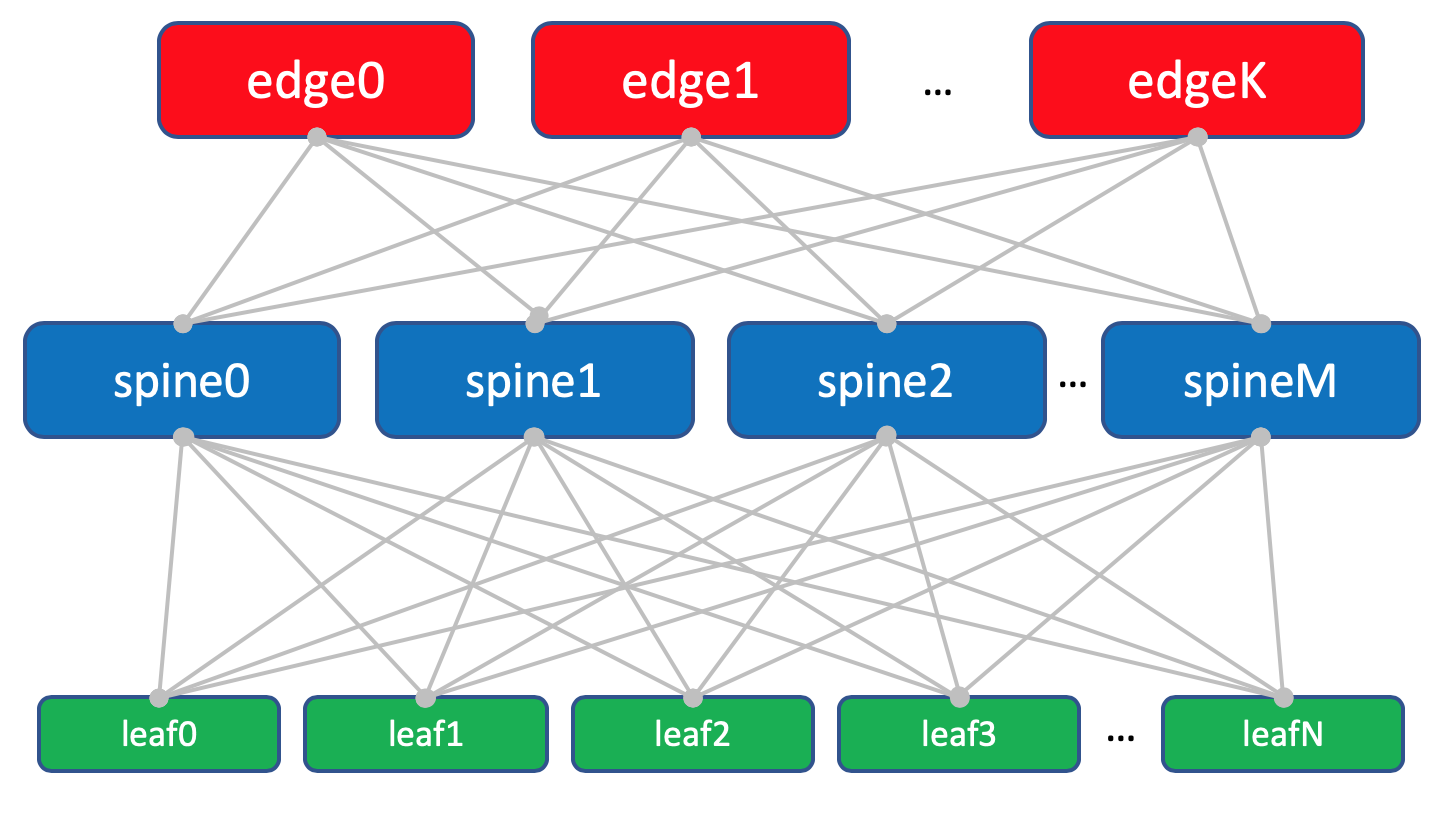
Spine: сравнительно простая железка, требующая самый минимум функций - её задача просто молотить трафик. Очень много и очень быстро. Зачастую это просто IP-маршрутизация. Но бывают и топологии, в которых Spine играет чуть более важную роль (VXLAN anycast gateway). Но обычная практика - держать конфигурацию спайнов максимально простой. Leaf: чуть более требователен к функциям. Может терминировать на себе VXLAN или другие оверлеи. Здесь могут реализовываться политики QoS и ACL. Зато не нужна такая большая пропускная способность, как для спайнов. Кроме того, в некоторых сценариях (VXLAN) leaf знает о сервисах за подключенными машинами (клиентских сетях, контейнерах), соответственно, ему нужно больше ресурсов FIB для хранения этой инфорации. Edge-leaf: это устройства границы сети ДЦ и здесь уже фантазия ограничивается только свободой мысли сетевых архитекторов - MPLS, RSVP-TE, Segment Routing, всевозможные VPN’ы. При этом наименее требовательны к производительности.
На каждом устройстве, соответственно, разные требования к возможностям чипов - как по пропускной способности, так и по набору функций и по количеству ресурсов для хранения чего-либо.

Всё более и более производительные чипы нужно выпускать уже примерно каждые полтора-два года.

Актуализированная мной картинка из видео PP.
Конкурирующие производители чипов идут ноздря в ноздрю - почти одновременно у всех (Broadcom, Mellanox, Innovium, Barefoot) выходят микросхемы с почти идентичными характеристиками, а вслед за ними и коммутаторы с ними.
Ещё одним компромиссным вопросом является размер буфера, но об этом мы поговорим попозже.
Для многих незаметно, но уже почти жизненно важно, начинает работать динамическая балансировка трафика: чип отслеживает потоки (flows) и дробит их на флоулеты (flowlets) - короткие куски трафика одного потока, разделённые между собой паузой в несколько миллисекунд. Эти флоулеты он может динамически распределять по разным путям (ECMP или членам LAG), чтобы обеспечить более равномерную балансировку. Особенно важно это для Elephant Flows, оккупирующих один интерфейс.
Пользователям всё чаще хочется иметь возможность управлять распределением буфера, ну а перераспределение ресурсов FIB - это уже функциональность, отсутствие которой будет вызывать вопросы.
В условиях датацентров ECMP и балансировка силами сети - это воздух, вендорам нужно обеспечить нужное количество как ECMP-групп, так и общее количество Next-hop’ов.
Посочувствуем же бедным вендорам и будем выбирать долларом.