Чипы памяти¶
Отдельно от микросхем логики (и вместе с тем с ними рядом), хочу посмотреть поближе на память.
У микросхем памяти широкое применение в сетевых устройствах.
Это не те таблицы, которыми пользуется чип коммутации - они слишком медленные, поэтому отдельная память устанавливается для хранения так называемых Hard Tables - таблиц для Forwardig Plane. Soft Tables из обычной памяти преобразются в Hard Tables.
Для быстрого поиска по таблицам (за константное время) были изобретены специальные виды памяти: CAM и TCAM.
Различного рода память нужна для буферизации пакетов на входе и на выходе из устройства, и для их хранения, пока обрабатываются заголовки. Это RAM, который может быть в формате GDDR-5/6, HMC, HBM/2.
Ниже мы взглянем на них чуть подробнее.
RAM - Random Access Memory¶
Классическая оперативная память - куда без неё?

Второй немаловажный компонент сетевого устройства, реализованный на RAM - это очереди: входные, выходные, интерфейсные. Пока пакет ожидает своего черёда на обработку, обрабатывается в чипе или ожидает своей отправки, он томится в RAM.
Эта память может быть на кристалле чипа коммутации, может быть под одной с ним крышкой, а может и просто находиться неподалёку на плате.
Типы этой памяти меняются в зависимости от задач: SDRAM, DDR, GDDR5, GDDR6, HMC, HBM.

У меня очевидная слабость к 3д-рендерам
К вопросу о RAM я ещё неоднократно вернусь ниже в секции “Packaging и Advanced Packaging” и вся глава “Память и буферы” посвящена этому.
CAM - Content-Addressable Memory¶

Note
Не путать данную RAM с RAM, содержащей Soft Tables, описанной выше - это разные компоненты, расположенные в разных местах.
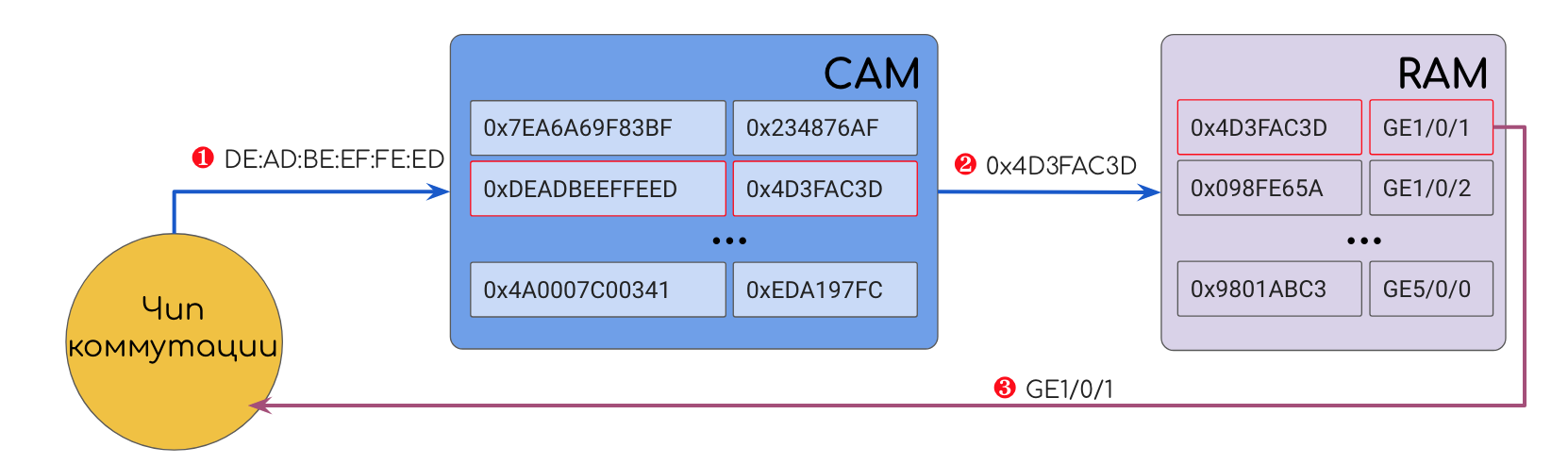
Вот архитектура такой памяти:
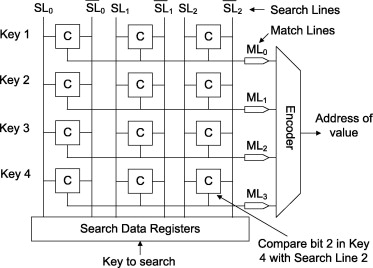
Вот пример работы
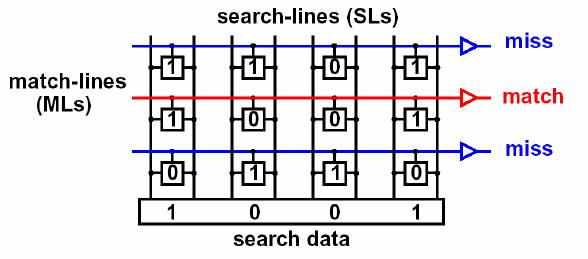
- А это схема реализации:
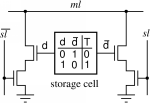
Это чем-то похоже на пару ключ-замок. Только ключ с правильной геометрией может поставить штифты замка в правильные положения и провернуть цилиндр. Вот только у нас много копий одного ключа и много разных конфигураций замков. И мы вставляем их все одновременно и пытаемся провернуть, а нужное значение лежит за той дверью, замок которой ключ откроет.
Для гибкого использования CAM мы берём не непосредственно значения из полей заголовков, а вычисляем их хэш. Хэш-функция используется для следующих целей:
- Длина результата значительно меньше, чем у входных значений. Так пространство MAC-адресов длиной 48 бит можно отобразить в 16-ибитовое значение, тем самым в 2^32 раза уменьшив длину значений, которые нужно сравнивать, и соответственно, размер CAM. Основная идея хэш-функции в том, что результат её выполнения для одинаковых входных данных всегда будет одинаков (например, как остаток от деления одного числа на другое - это пример элементарной хэш функции).
- Результат её выполнения на всём пространстве входных значений - это ± плоскость - все значения равновероятны. Это важно для снижения вероятности конфликта хэшей, когда два значения дают одинаковый результат. Конфликт хэшей, кстати, весьма любопытная проблема, которая описана в парадоксе дней рождения. Рекомендую почитать Hardware Defined Networking Брайна Петерсена, где помимо всего прочего он описывает механизмы избежания конфликта хэшей.
- Независимо от длины исходных аргументов, результат будет всегда одной длины. То есть на вход можно подать сложное сочетание аргументов, например, DMAC+EtherType, и для хранения не потребуется выделять более сложную структуру памяти.
Именно хэш закодирован в сравнивающие элементы. Именно хэш искомого значения будет сравниваться с ними. По принципу CAM схож с хэш-таблицами в программировании, только реализованными на чипах.
В этот принцип отлично укладывается также MPLS-коммутация, почему MPLS и сватали в своё время на IP.
Например:
- Пришёл самый первый Ethernet-кадр на порт коммутатора.
- Коммутатор извлёк SMAC, вычислил его хэш.
- Данный хэш он записал в сравнивающие элементы CAM, номер интерфейса откуда пришёл кадр в RAM, а в саму ячейку CAM адрес ячейки в RAM.
- Выполнил рассылку изначального кадра во все порты.
- Повторил пп. 1-5 ….
- Заполнена вся таблица MAC-адресов.
- Приходит Ethernet-кадр. Коммутатор сначала проверяет, известен ли ему данный SMAC (сравнивает хэш адреса с записанными хэшами в CAM) и, если нет, сохраняет.
- Извлекает DMAC, считает его хэш.
- Данный хэш он прогоняет через все сравнивающие элементы CAM и находит единственное совпадение.
- Узнаёт номер порта, отправляет туда изначальный кадр.
Резюме:
- Ячейки CAM адресуются хэшами.
- Ячейки CAM содержат (обычно) адрес ячейки в обычной памяти (RAM), потому что хранить конечную информацию в CAM - дорого.
- Каждая ячейка CAM имеет на входе сравнивающий элемент, который сравнивает искомое значение с хэш-адресом. От этого размер и стоимость CAM значительно больше, чем RAM.
- Проверка совпадения происходит одновременно во всех записях, отчего CAM дюже греется, зато выдаёт результат за константное время.
- CAM+RAM хранят Hard Tables (аппаратные таблицы), к которым обращается чип коммутации.
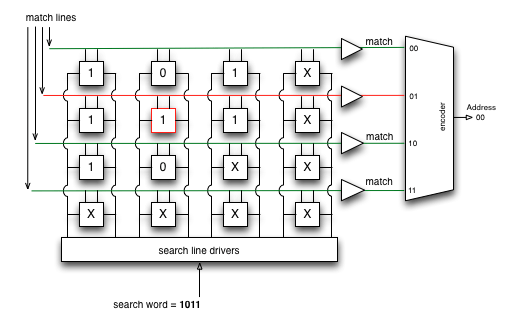
TCAM - Ternary Content-Addressable Memory¶
CAM весьма неплохо подходит для поиска MAC-адресов, где результат всегда заведомо один. А что не так с IP
- Как это в принципе реализовать?
- Как из нескольких подходящих маршрутов выбрать лучший (с длиннейшей маской)?

0.0.0.0/0 10.10.10.8/29 10.10.0.0/16 10.8.0.0/13 Другие
Алгоритмический поиск¶
Прогресс, как говорится, не стоит на месте. Появляются новые алгоритмы, совершенствуются старые. Чипы становятся всё более производительными иногда даже более дешёвыми. TCAM - вещь элегантная, но экономически не очень выгодная. И как только первый вендор реализовал алгоритмический поиск и стал продавать своё оборудование дешевле конкурентов с TCAM, все начали делать так же.
Суть этого подхода в том, что вместо прожорливого до денег и электричества TCAM ставится отдельный ASIC, реализующий алгоритмический лукап IP-адреса (или чего-то ещё) и тот же RAM рядом.
TCAM всё ещё применяется в сетевом оборудовании для узкоспециалиазированных задач.
Подробнее послушать о алгоритмах этого класса и деревьях можно в подкасте с Кодом Безопасности.