Физическое устройство¶
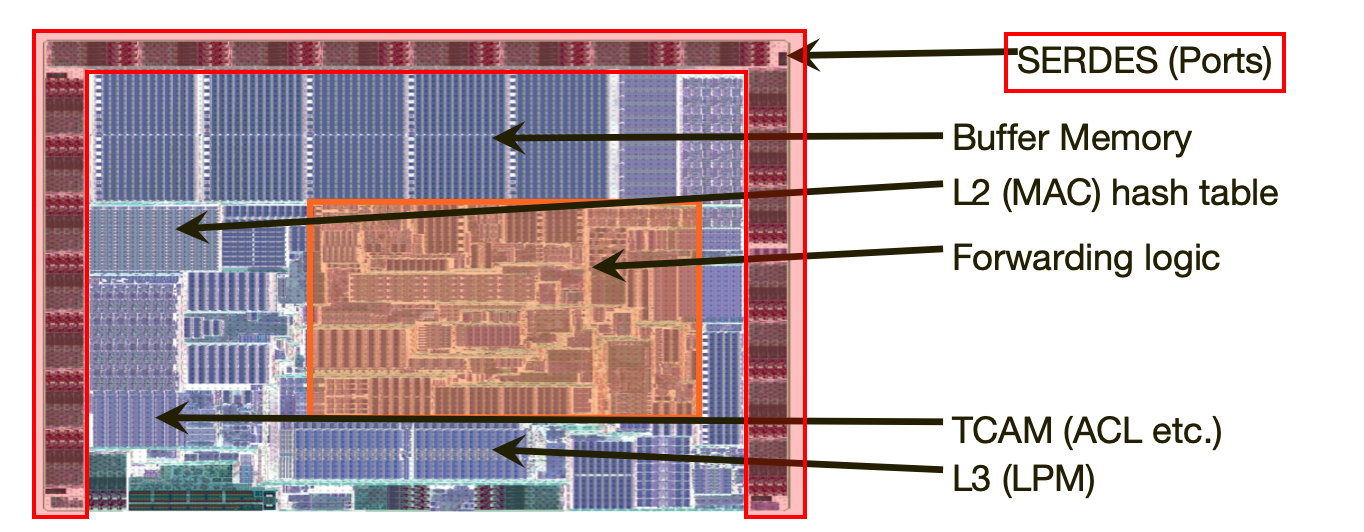
Итак, для успешной коммутации пакета нужны следующие блоки:
- Парсер заголовков (Parser)
- Лукап (Match): FIB/LFIB, Nexthop-группы, ARP Adjacencies, IPv6 ND Tables, ACL итд
- Блоки преобразований (Action)
- Блок управления памятью (TM/MMU)
- Сборщик пакета (Deparser)
- SerDes
- Память для буферизации пакетов
- Блок, реализующий MAC
- Чип PHY
- Физические порты/трансиверы
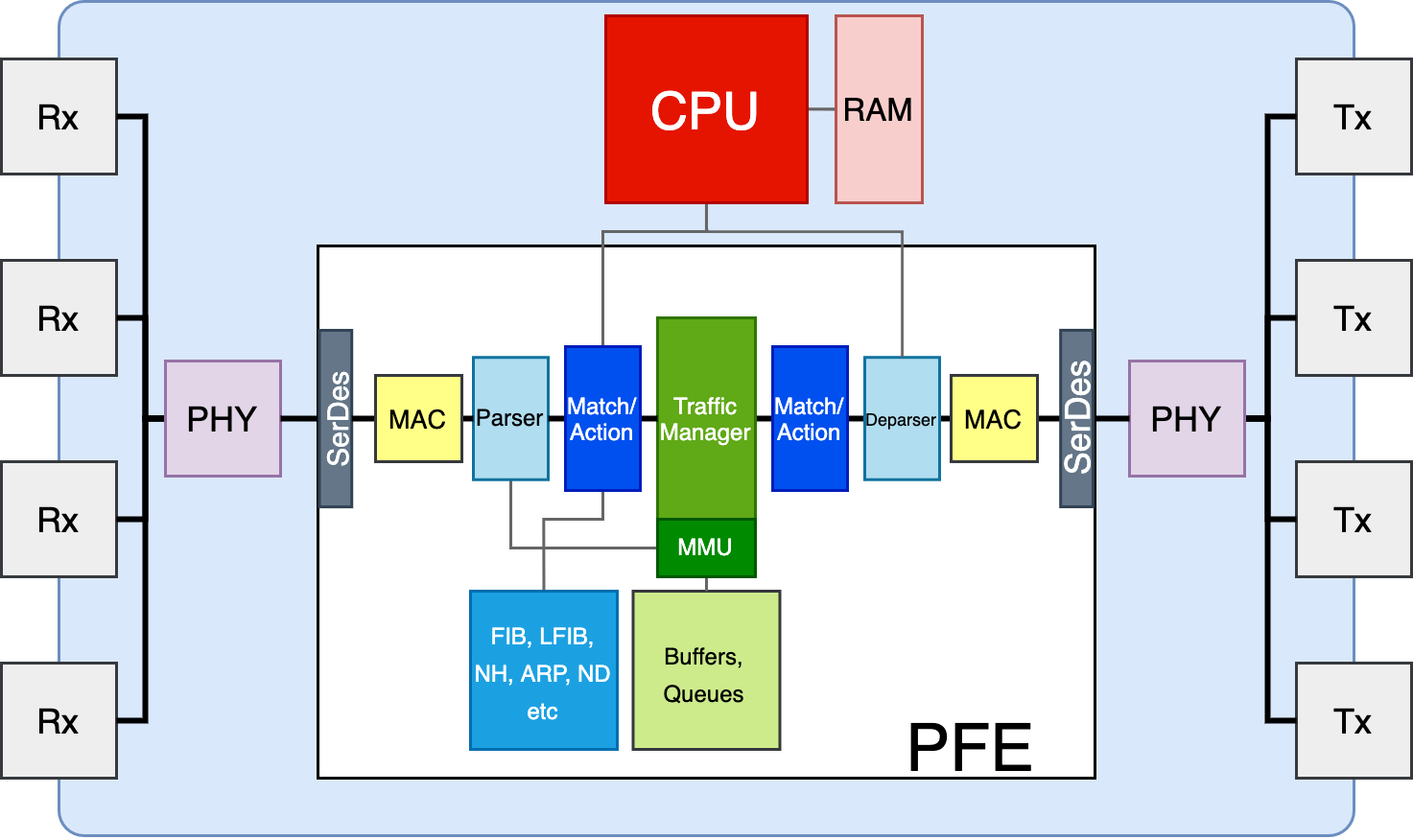
Крупными мазками: оптический или электрический сигнал попадает на порт (Rx), тот его передаёт на PHY. Модуль PHY реализует функции физического уровня и передаёт биты на входные пины PFE, где сигнал блоками SerDes преобразуется в удобоваримый для чипа вид. Блок MAC из потока битов восстанавливает Ethernet-кадр и передаёт его парсеру. Парсер отделяет необходимые ему заголовки и передаёт их на анализ следующему блоку Match/Action. Тот их исследует и применяет нужные действия - отправить на правильный порт, на CPU, энкапсулировать, дропнуть итд. Тело пакета всё это время хранилось в буферах, управляемых MMU, и теперь пришло время Traffic Manager’у проводить все обряды QoS. И потом процесс раскручивается в обратную сторону. Снова Match/Action. Потом собрать пакет с новыми заголовками (Deparser), преобразовать кадр в поток битов (MAC), сериализовать (SerDes), осуществить действия физического уровня (PHY) и передать через выходной порт (Tx) в среду.
В простейшем случае вообще почти все блоки являются частью одного монолитного кристалла кремния. То есть они - продукт одного процесса печати на вафле.
Отдельные, составляющие чип компоненты, реализующие законченный набор функций, называются IP-core (не тот, что ты мог подумать, сетевой инженер!). То есть SerDes, MAC, TM - это всё отдельные IP-core. Зачастую они производятся сторонними компаниями, специализирующимися конкретно на данных компонентах, а потом встраиваются в микросхему. Особенно это касается SerDes - сложнейшей детали, в которую вендоры сетевых чипов не готовы вкладывать силы R&D. Один из крупных производителей SerDes - Inphi.
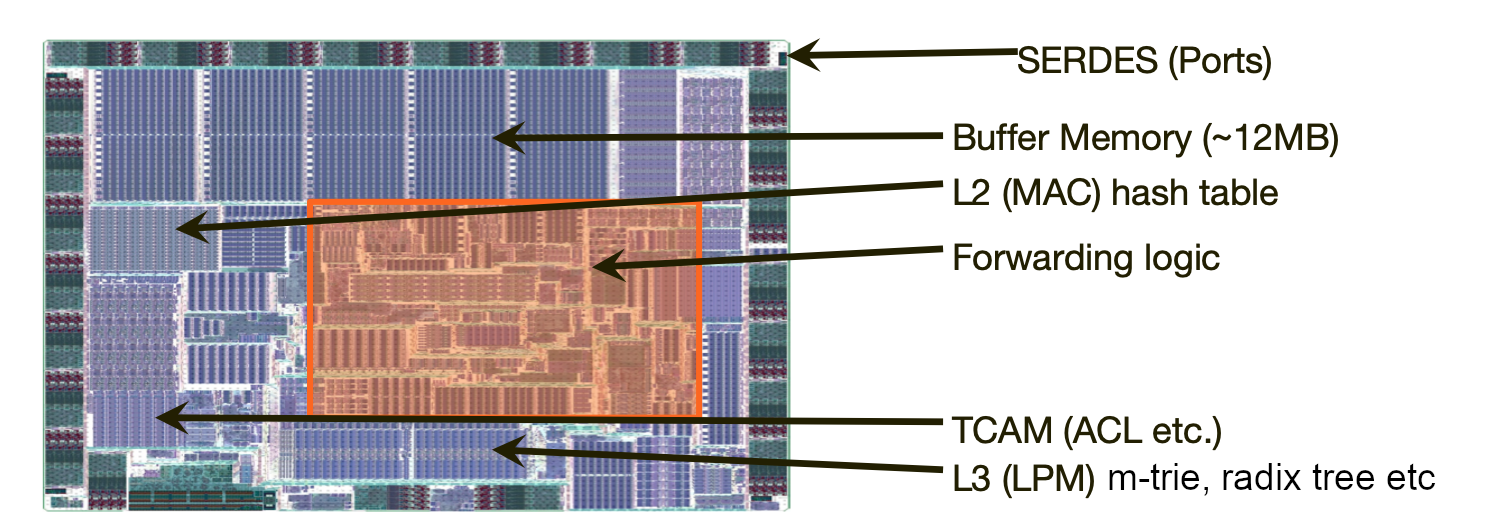
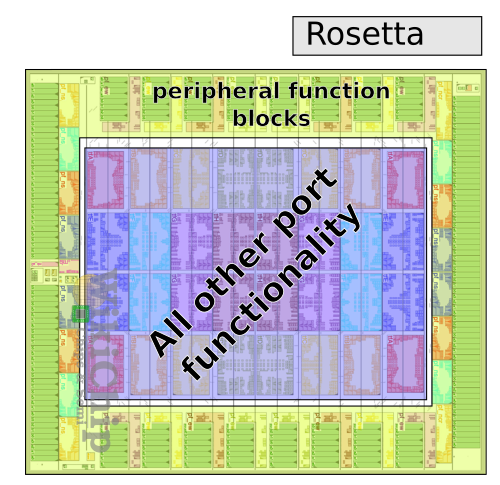
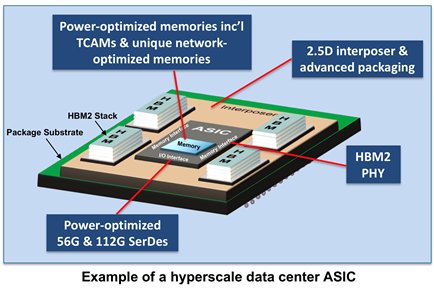
Другой распространённый вариант: в одном чипе сочетать несколько разных кристаллов с интерконнектом между ними. Так, например, память HBM коммерческого производства выносится за пределы кристалла сетевого ASIC:
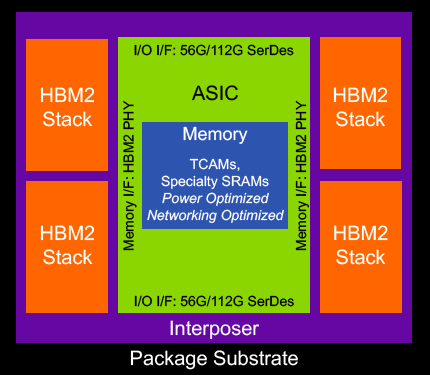
Под крышкой одного производительного чипа могут быть собраны несколько, так называемых, менее производительных чиплетов (chiplet), которые, объединённые в фабрику, дают бо́льшую пропускную способность:
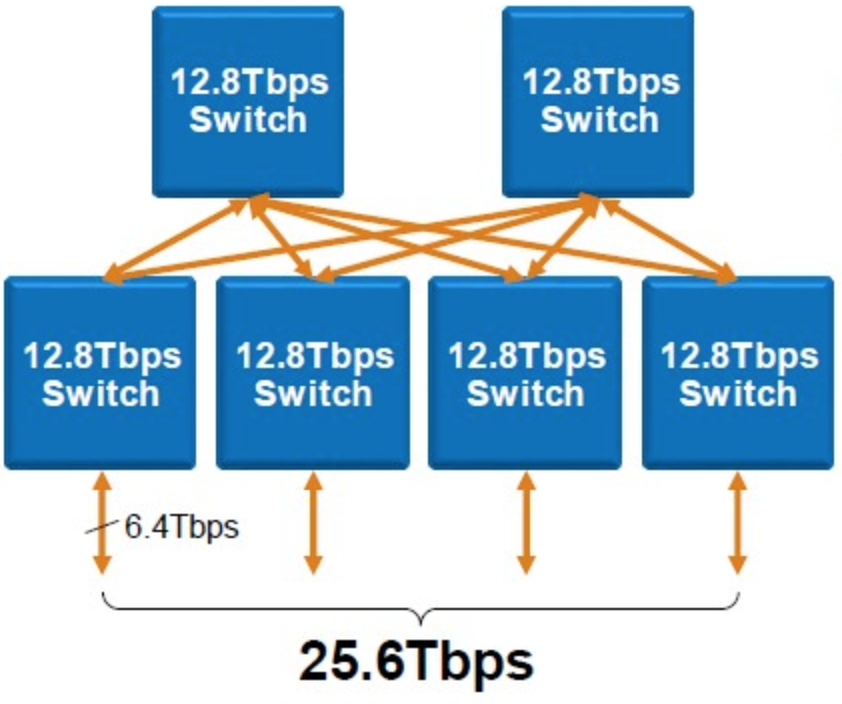
Для некоторых решений рядовая практика - вообще все ресурсы выносить за пределы сетевого ASIC’а:

В случае Juniper, кстати, их Trio - это не один ASIC - это их набор, каждый из которого реализует свои функции.
Но как бы ни был устроен сам чип, ему нужно общаться с миром. И поэтому на животике у него есть несколько тысяч пинов:

Одни пины нужны для того, чтобы подключить к чипу интерфейсы. Другие - чтобы подключиться к внешней памяти (CAM/TCAM/RAM), если она есть. Третьи - к фабрике коммутации, если коробка модульная.
Два пина образуют дифференциальную пару для передачи данных в одном направлении. То есть две пары пинов нужны для полнодуплексной передачи.
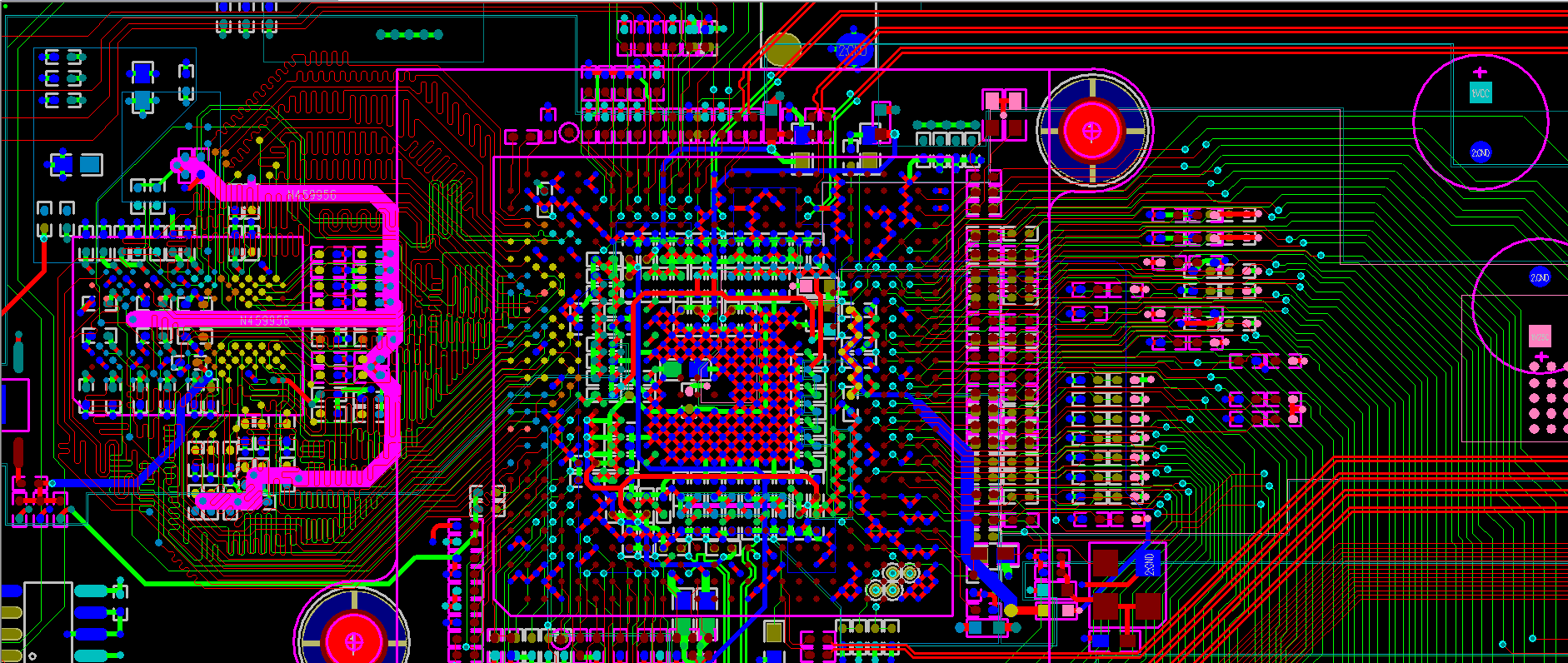
Вот так оно потом выглядит в программах для проектирования (для случая на порядок более простой микросхемы):
Теперь пришло время разобраться с тем, что же такое загадочный SerDes. Нет, это не ножки на микросхеме.
SerDes¶
Если коротко - то это блоки (IP-core) сетевого ASIC’а, которые позволяют получить сигнал с пинов и, наоборот, передать его туда.
Теперь с этимологией. Аналогично “модему” и “кодеку”, ставшим уже такими родными в кириллическом написании, SerDes составлен из двух слов: Serializer-Deserializer. Так чего же он сериализует и десериализует?
Блоки SerDes всегда являются составными частями кристалла сетевого чипа.
Выглядит довольно сложным. Для чего же вообще устраивать эту сериальную вакханалию, а не сделать просто пинов по числу реальных линий в чипе?
Зачем?¶
Модуляция¶
Итого, учитывая современные реалии (NRZ), для того, чтобы запитать данными интерфейс 100Гб/с нужно подвести к нему 4 SerDes’а по 28Гб/с (или 16 дорожек). Отсюда и берётся “лейновость” 100Ж-портов: 4 лейна - это 4 канала по 28Гб/с.
И это то, что позволяет 1х100Ж порт разбить на 4х25Ж с помощью гидры.

В случае PAM4 для 100Ж нужно только 2 SerDes’а по 56Гб/с, то есть два лейна.
GearBox’ы¶
Сложности с переходом на новые методы модуляции заключаются в том, что устройства на разных сторонах должны использовать одинаковые, либо нужно ставить дополнительные конвертеры. То есть просто подключить сотками коммутатор с PAM4 к NRZ не получится.
Ну а потом от вещей мирских перейдём к тому, сколько кругов пакет проходит в чипе.
PHY¶
- Конвертация сигнала между средами (оптика-медь), если это нужно
- Восстановление битов из сигналов и наоборот
- Коррекция ошибок
- Синхронизация
- И другие задачи физического уровня.
Если хочется знать больше, и не пугают забористые тексты со страшными картинками: PHY Interface for PCI Express, SATA, USB 3.1, DisplayPort, and Converged IO Architectures.
Что действительно любопытно и достойно обсуждения - так это его расположение. Если порт медный - RJ45, то чип PHY - это ASIC, установленный на плате.

Если порт оптический, то в подавляющем большинстве случаев эти функции возьмёт на себя DSP PHY, встроенный в трансивер (та самая штука, называемая нами модулем и вставляемая в дырку в коммутаторе).

Однако тенденции последних лет - это Silicon Photonics.
В случае silicon photonics микросхема PHY переносится внутрь самого чипа коммутации. В кристалл “встраиваются” фотонные порты, позволяющие осуществлять коммуникации между чипами на скорости света через оптическую среду.
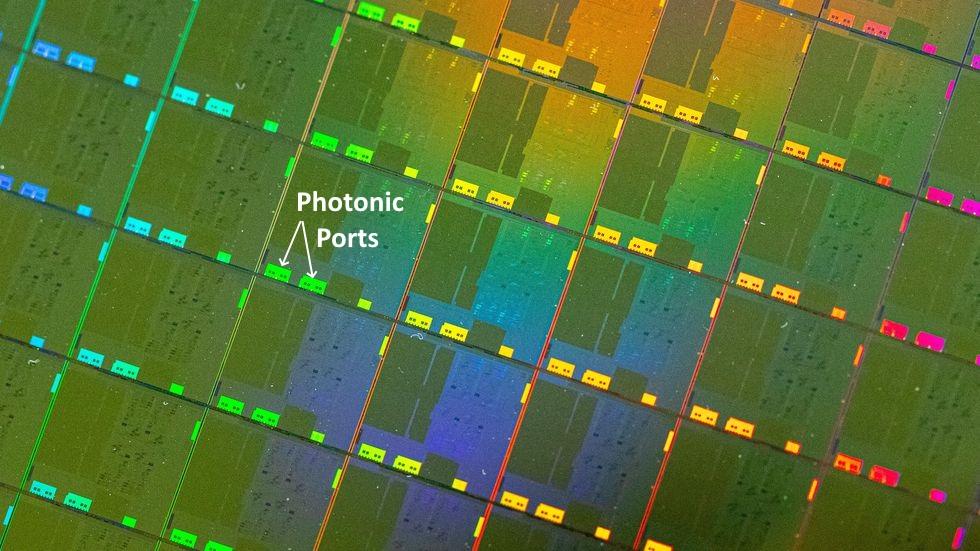
Идея не новая, и только ожидавшая своего времени, а именно, когда технологии достигнут нужного уровня зрелости. Проблема была в том, что материалы и процессы, используемые для производства фотонных чипов, были фундаментально несовместимы с процессом производства кремниевых чипов - CMOS.
Из возможных альтернативных решений: установка на плату отдельного чипа, преобразующего электрический сигнал в оптический, или его установка внутрь сетевого чипа, но не на сам кристалл (всё ещё требует конвертации среды).
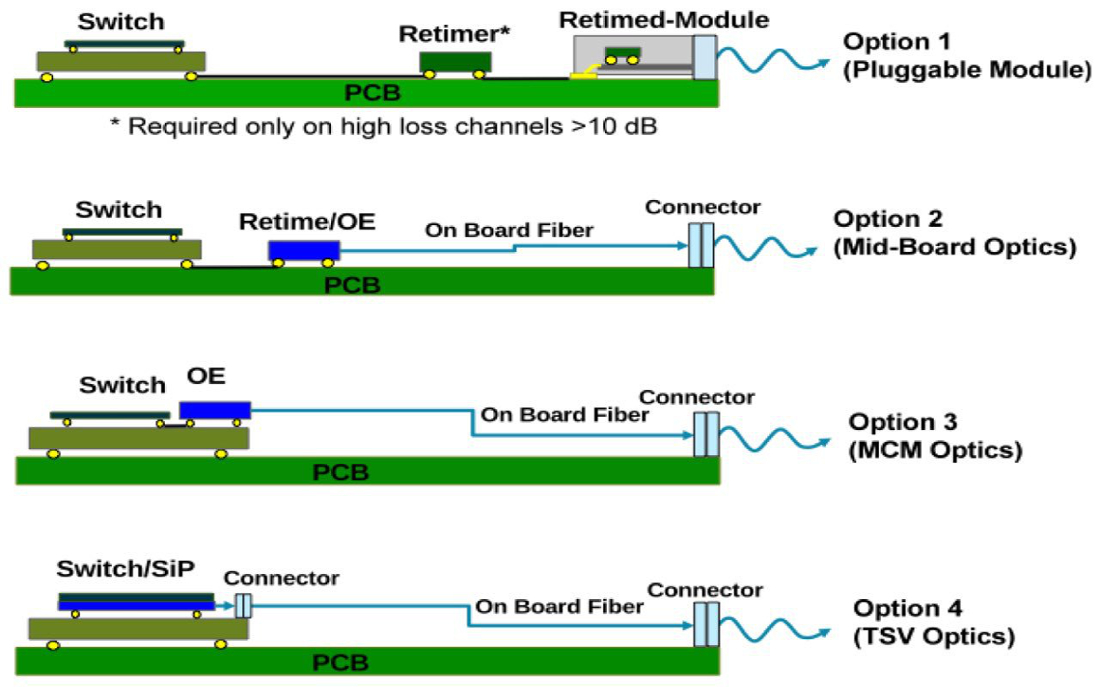
Но эта технологическая плотина смыта упорными разработками в этом направлении, и в скором будущем микроэлектронику ждут большие изменения.
Весьма занимательная статья с историей вопроса и сегодняшними реалиями.
Note
Кстати, был у нас в гостях Compass EOS, которые разработали co-packaged optics ещё до того, как это стало модным. Но, увы, они настолько опередили своё время, что оказались в тот момент никому не нужны. И постигла их ужасающе печальная судьба быть купленным не то Ростелекомом, не то Роснано. Впрочем, возможно, история звучала совсем иначе :).
Note
И прямо во время написания этой статьи 5-го марта 2х20 Intel опубликовал в своём блоге новость о том, что они продемонстрировали первый свитч, в котором им удалось интегрировать свой интеловский silicon photonics в барефутовский Tofino2.

Напоследок хочется немного времени посвятить прям совсем кишочкам, скрытым под металлической крышкой.
Packaging и Advanced Packaging¶
Packaging (корпусирование) - это процесс упаковки кристалла в корпус, который защитит его от физических повреждений и коррозии.

Я честно предпринял попытку разобраться в этом вопросе, но уже на втором часе чтения стало понятно, что, если хоть немного глубже общих понятий погружаться, то это будет требовать ещё одной статьи такого же размера, чтобы не прослыть дилетантом.
Когда-то давно, внутри одной микросхемы на плате был один кристалл. Даже не так - когда-то давно в микросхеме было несколько полупроводниковых элементов.

Нужно две микросхемы - ставим их рядом, соединяем дорожками.

Нужно много-много микросхем - делаем большие платы или собираем платы в несколько слоёв.

Со временем транзисторы становились меньше, а микросхемы сложнее - внутри одного кристалла могли совмещаться несколько логических блоков - это были первые SoC - System On Chip - ЦПУ+Память+какие-нибудь специфические задачи. Но сильно много туда всё равно не засунешь.

Потом научились, нарезав вафли на отдельные кристаллы, каждый из них запаковывать в отдельный пластиковый пакет, ставить один на другой и корпусировать вместе. Толщина таких бутербродов получалась большой - заметно больше, чем толщина ядра.
Что сделало возможными семимиллиметровые телефоны - так это Wafer-Level Packaging (WLP) или ещё это называют Advanced Packaging - технологии, позволяющие на одной вафле делать несколько микросхем и связывать их друг с другом. Сюда относятся: 2D, 2.5D, 3D, Fan-Out, 2.1D итд.
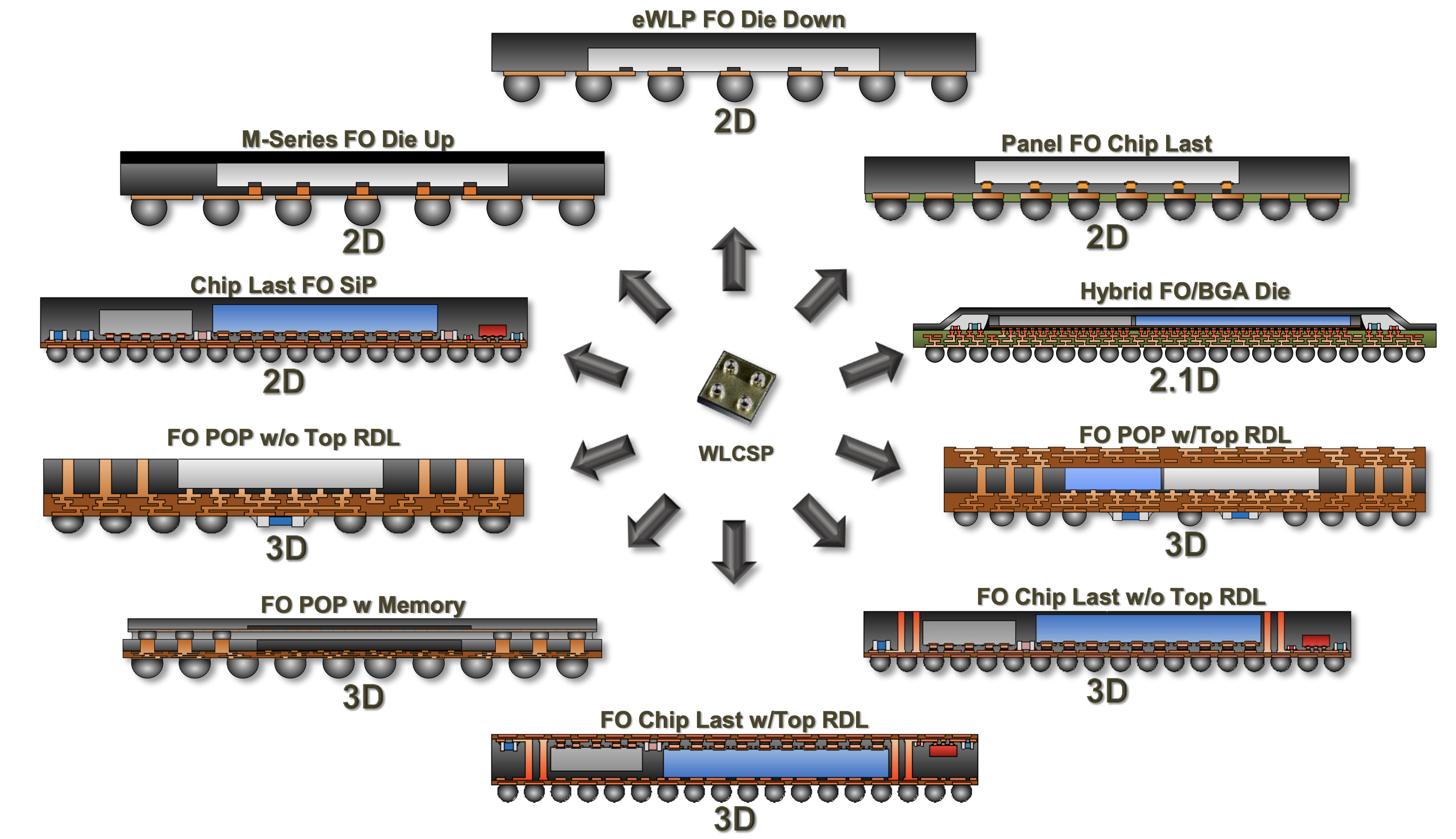
Каждый отдельный чип называется чиплетом (chiplet). Отличаются технологии Advanced Packaging’а друг от друга расположением чиплетов (рядом или один на другом), наличием и отсутствием интерпозера, материалом интерпозера (кремний, стекло, органика), видом электрических связей между кристаллами (металлические дорожки или TSV) и массой других. Суть их всех в том, что такая более плотная компоновка позволяет уменьшить размер, увеличить количество шин передачи данных, а соответственно и пропускную способность, значительно сократить энергопотребление и тепловыделение, отказавшись от длинных металлических дорожек.
Зачем я вообще в это решил копнуть? Во-первых, теперь немного понятнее становится что такое co-packged optics из предыдущего параграфа - это чиплет, реализующий оптический интерфейс, упакованный по одной из этих схем внутрь чипсета с ASIC’ом. А, во-вторых, дальше я буду рассказывать о памяти и буферах. Также я скажу о том, что каждый коммутационный ASIC обладает небольшим объёмом встроенной памяти - On-Chip Buffer. Она является составной частью асика коммутации.
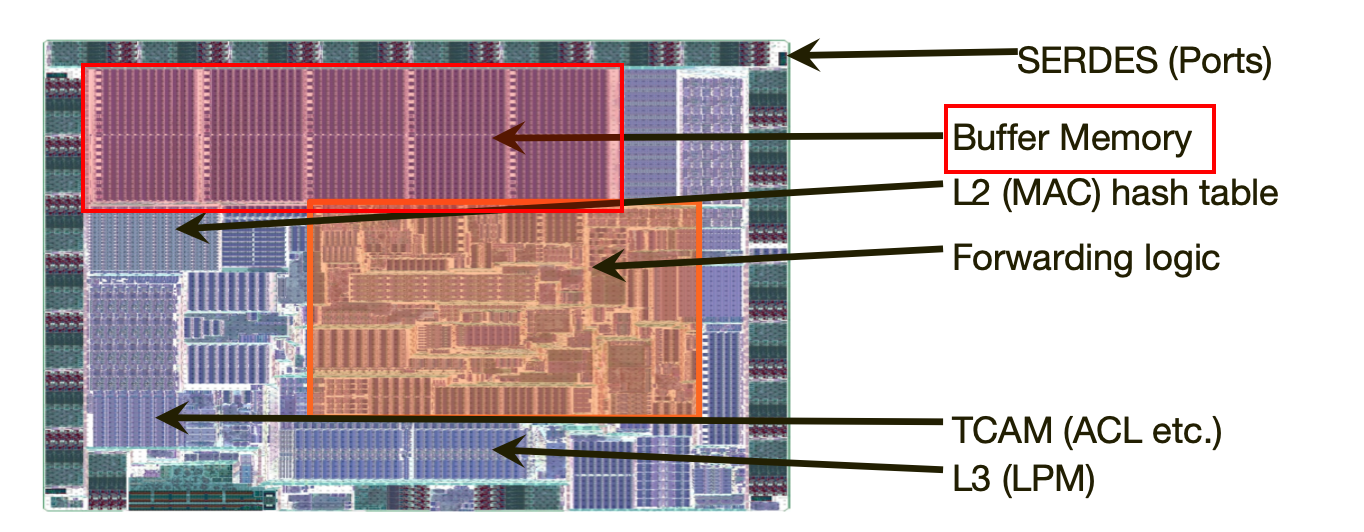
Однако в некоторых случаях в помощь к ней добавляют объёмную внешнюю память, в которой пакеты будут храниться, если они не помещаются во встроенную. И пока это была какая-нибудь GDDR5, вынесенная отдельно на печатной плате в виде самостоятельного чипа, всё было понятно.

Своего родного сетевого не нашлось, но вот тут карточка от Энвидии с вынесенными GDDR5.
Но сегодня, с появлением WLP, когда под одной крышкой собраны и логика и память, границы начинают размываться. Некоторые вендоры спекулируют тем, что внешняя память co-packaged с коммутационным ASIC’ом, и утверждают, что она On-Chip.
Так, например, выглядит 2.5D корпусирование, где один чиплет соединён с другим через кремниевый интерпозер:
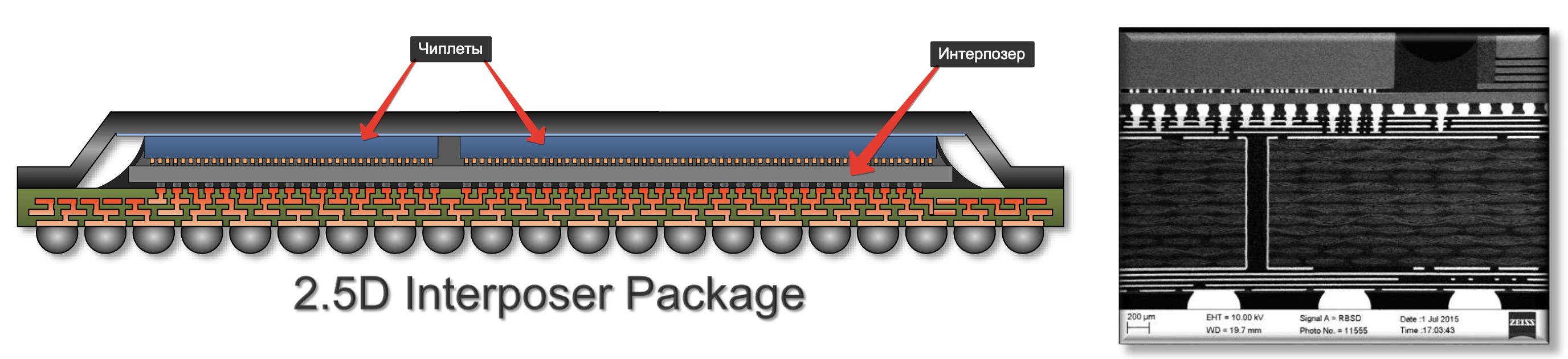
2.5D - это развитие классического подхода 2D. Оно всё ещё требует дорогостоящего выхода за пределы чиплета и прохода по длинным металлическим дорожкам. И кроме того обладает сравнительно невысокой пропускной способностью, ограничивающей максимальную скорость, на которой может работать чип в условиях, близких к перегрузкам.
Другой вариант - это уже 3D WLP:
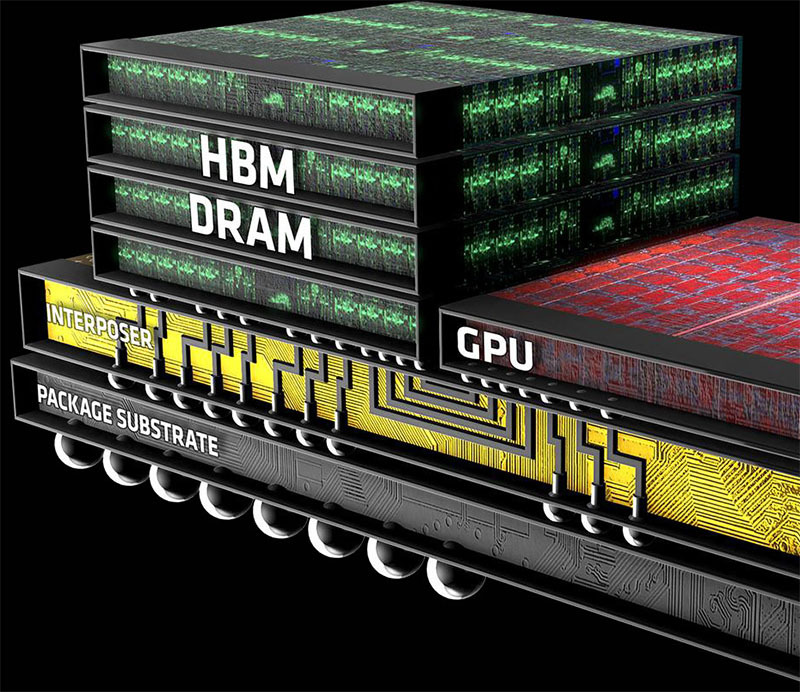
Вот “более настоящая” схема устройства чипа Broadcom Jericho2. Здесь несколько чиплетов памяти HBM стекированы один на другой по технологии 3D, а сам чип коммутации с этим блоком внешней памяти взаимодействует через интерпозер.
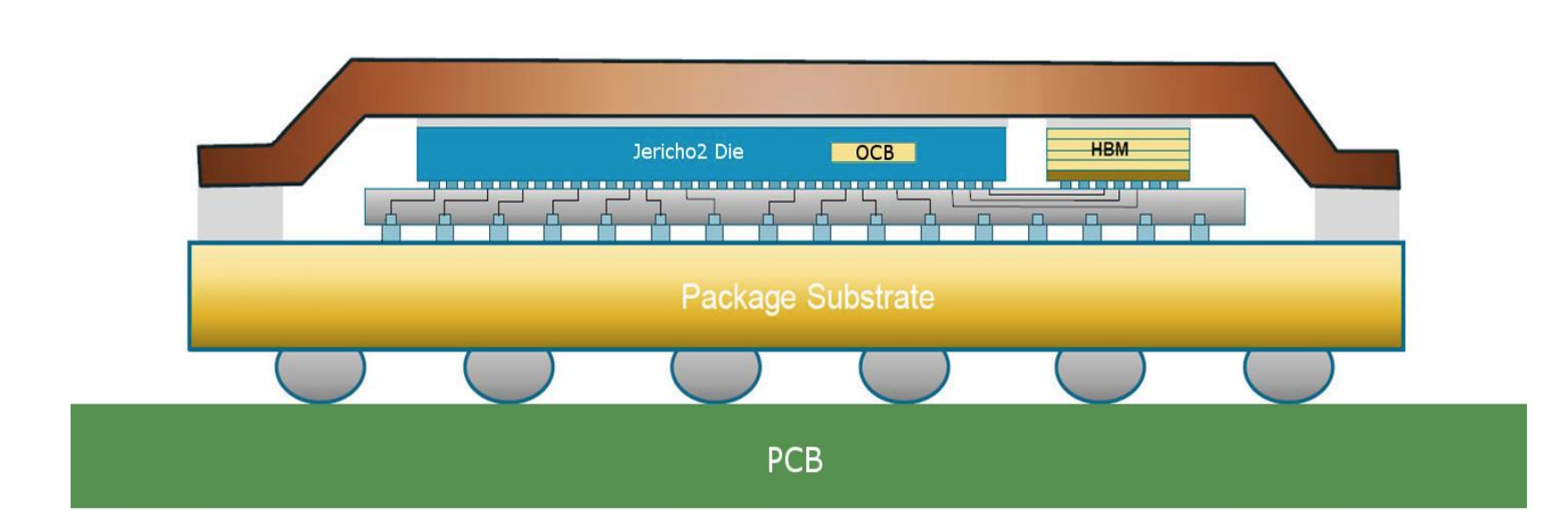
- А вот совсем уж настоящее фото чипсета Juniper ZX EXPRESS, совмещающего память и ASIC под одной крышкой:

HBM - High Bandwidth Memory - как раз и является High Bandwidth благодаря очень широким шинам взаимодействия между плотно скомпонованными чиплетами.
Расположенные друг над другом они соединены через TSV - Through-Silicon Via - это микроскопические проходные отверстия в кристаллах, залитые металлом (например, вольфрамом), которые позволяют чипам общаться друг с другом. Они значительно короче линий в интерпозере, что позволяет их сделать гораздо более эффективными.

HBM весьма уверенно пробивает себе дорогу сегодня в мир Deep-Buffer!!! коробок.
Кстати по такой же 3D-технологии корпусирования была создана память HMC - Hybrid Memory Cube. Это бутерброд из склееных друг с другом плашек DRAM, пронизанных TSV.
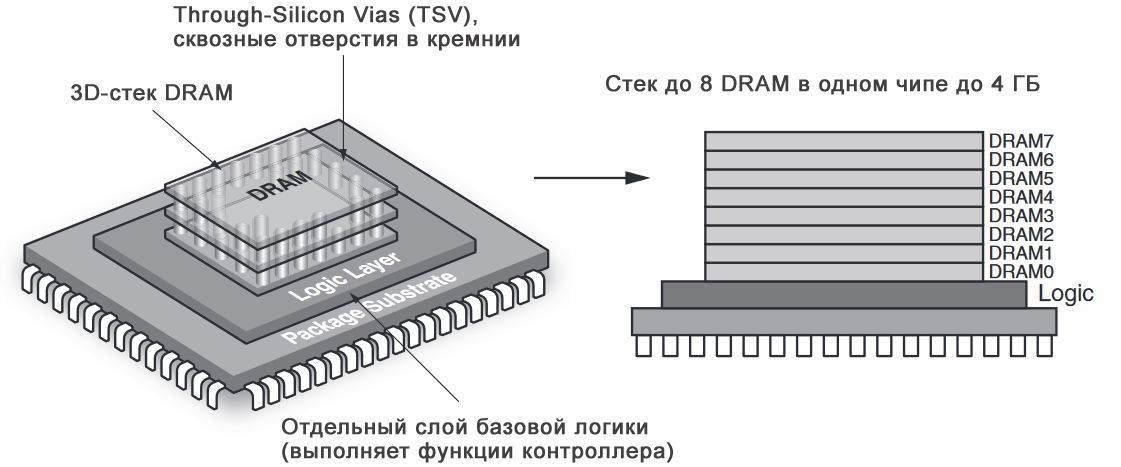
HMC - это коммерческая память производства Micron, от которой ныне отказались в пользу HBM и GDDR6.
Считать ли такую компоновку действительно On-Chip или нет - вопрос открытый, но складывается мнение, что в будущем необходимая от ASIC’а скорость коммутации будет расти всё равно быстрее, чем пропускная способность интерфейса до пусть даже лежащего плотно на ней чиплета HBM.
Дальнейшее чтиво: