Pipeline¶
Пайплайном называется весь процесс доставки пакета от парсера до депарсера. Что хорошо - можно делать несколько Match-Action подряд, например, отлукапив сначала Ethernet, потом IP, потом ещё и TCP для ECMP.
Что плохо - число этих действий строго ограничено - ASIC вещь достаточно детерминированная. Это ведёт к тому, что некоторые вещи становятся аппаратно невозможны. К примеру, на старых Trident’ах нельзя было сделать и VXLAN и IP lookup последовательно для одного пакета. Или в другой ситуации коробка у меня не могла снять метку, сделать рекурсивный IP-lookup и навесить две новые метки.
Однако у таких трудностей есть как минимум три решения:
- Второй чип. Тогда можно и разнести невозможные прежде операции на два этапа. И история знает такие решения.
- Рециркуляция. Многие чипы позволяют закольцевать выход чипа на вход и прогнать пакет дважды. Тогда на второй итерации ему можно задать уже другой набор Match-Action. Но за это придётся заплатить - удвоенной задержкой и уменьшенной полосой пропускания чипа. А ещё можно упереться и в пропускную способность самого рециркулятора.
- Купить другой чип… Другой коммутатор… Поменять работу…
Programmable Pipeline¶
В большинстве современных коммутаторов конвейер обработки пакетов запечён производителем в софт (если не в кремний) - он фиксирован и может быть изменён только вендором чипсета.
Attention
Не путать с Programmable ASIC. Программируемые микросхемы - уже давно реальность. Многие сетевые чипы - это ASIC с возможность программирования. Но эта возможность есть только у производителя микросхемы.Порграммируемый конвейер же - это возможность изменять логику работы чипа в определённых пределах, которую предоставляет производитель микросхемы покупателям.
Не так давно появился Barefoot Tofino, у которого полностью программируемый Pipeline - с ним можно задавать совершенно любые условия для парсера, поля для Match и действия для Action - хоть калькулятор пишите, или распределённое хранилище на кластере коммутаторов.
На сегодняшний день выпускать сетевую микросхему на рынок без возможности программирования Pipeline’а, становиться плохим тоном. Так, последние чипы Broadcom тоже уже программируемы.
Не то чтобы теперь каждый домовой оператор кинется переписывать себе пайплайны, нанимая студентов для разработки под P4 или NPL, но это возможность, которая позволяет вендорам железа и крупным потребителям вроде гугла быть гораздо более гибкими. Так, например, если в вашей сети все линки p2p, то зачем вам Ethernet? тратить на него такты ASIC’а ещё - просто выкидываем его.
Правда “можно всё запрограммировать” превращается в наших реалиях “придётся всё запрограммировать”. На сегодняшний день готовых конструктивных блоков, вроде парсинга Ethernet, IP, подсчёта статистики итд - не существует - всё с нуля. Если не использовать вендорские бинари, то весь Pipeline придётся написать самому. А если использовать, то ничего за пределами SDK не запрограммируешь.
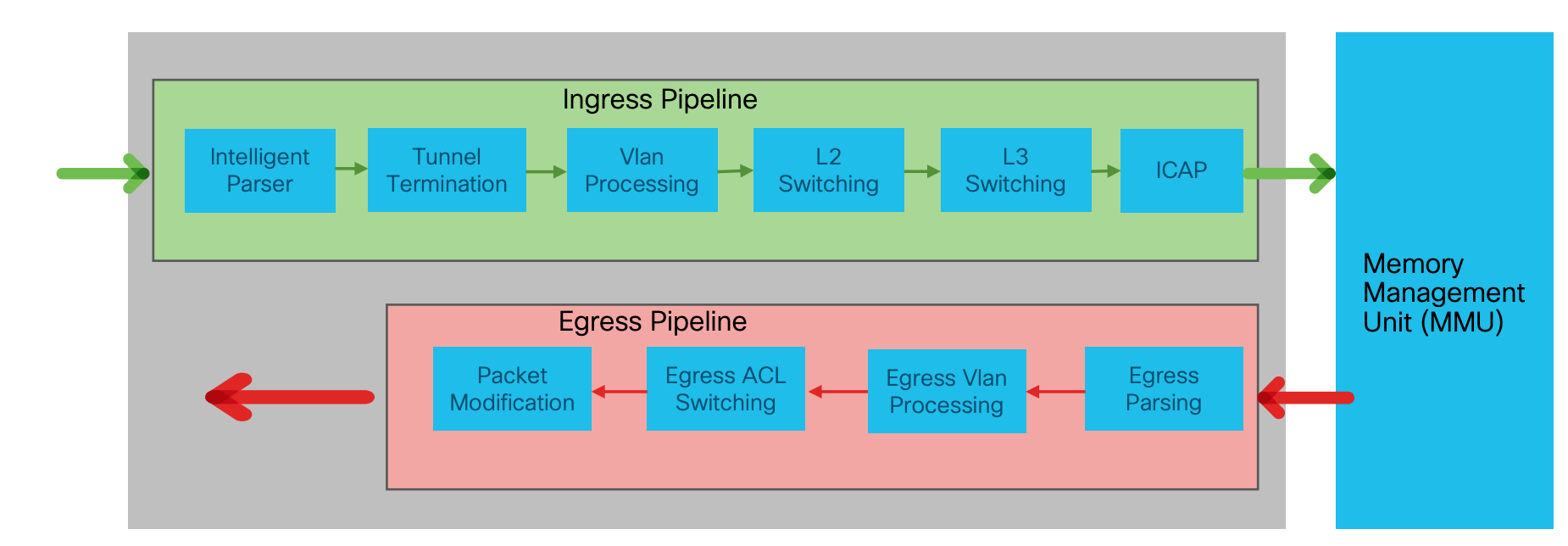
Но на большинстве современных коммутаторов всё ещё фиксированный конвейер, который выглядит примерно так:
Дальнейшее чтиво:
- Cisco всё ещё делает классную документацию, а презентации с Cisco Live - кладезь технических сокровищ. Например, они рассказывают о бродкомовских чипах больше, чем сам Бродком (если, конечно, вы не подписали NDA кровью): Cisco Nexus 3000 Switch Architecture
- Вот у P4 есть неплохое описание конвейера и его программируемости: P4 Tutorial, Hot Chips 2017.
- Более фундаментальное и низкоуровневое описание RMT - Reconfigurable Match Tables, необходимых для возможности программирования: Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN.