Перегрузки: причины и места¶
Буфер нужен на сетевом устройстве не только для того, чтобы похранить тело пакета, пока его заголовки перевариваются в кишках чипа.
Как минимум нужно сгладить поток пакетов до скорости выходного интерфейса. Грубо говоря, пока один пакет сериализуется для передачи в интерфейс, второму нужно где-то подождать.
Для этой задачи обычно хватит совсем небольшой FIFO очереди.
Другая важнейшая сетевая задача - перегрузки (congestion). Если в один интерфейс одновременно сваливается много пакетов, их тоже нужно сохранить.
Причём перегрузки - это наша повседневная легитимная реальность, а не что-то крайне редкое, что нужно перетерпеть и станет попроще.
Во времена коммутации каналов такой проблемы не стояло - для любой общающейся пары всегда было зарезервировано строго необходимое количество ресурсов.
Сегодня совершенно законно на порт может прийти больше трафика, чем тот готов сиюминутно пропустить.
Причины перегрузок¶
Самая простая - из высокоскоростного интерфейса трафик должен слиться в более низкоскоростной - из 10G в 1, например.
Другая причина, очень распространённая в сетях крупных ДЦ, особенно в тех, где развёрнуты кластеры Map-Reduce - это Incast. Это ситуация, в которой одна машина отправляет запрос на десятки/сотни/тысячи, а те все разом начинают отвечать, и пакеты стопорятся на узком интерфейсе в сторону машины-инициатора.
Более общий случай - трафик с нескольких входящих портов должен влиться в один исходящий - Backpressure.
Прочие типы всплесков трафика, которые ещё называют бёрстовыми или просто бёрстами (Bursts).
Поэтому однозначно нужно побольше памяти для буферизации. Но фактически это место, где пакеты обрастают задержкой.
Так на заре 1G буферизация вызывала массу головной боли у трейдеров, чьи приложения получали свой бесценный трафик с задержкой и джиттером.
И поэтому тут уже недостаточно везде FIFO. Это задача, во благо которой трудится QoS.
Если случилась конгестия, то нужно иметь возможность требовательный к задержкам трафик, пропустить первым, чувствительный к потерям - не дропнуть, а наименее ценным пожертвовать.
Ещё нужно уметь пополисить и пошейпить.
Но в каком месте располагать эту память и где реализовывать QoS?
Места возникновения перегрузок¶
Их по большому счёту 4:
- на входном чипе - если со стороны интерфейсов на него поступает больше, чем он способен обработать.
- на фабрике коммутации (если коробка модульная) - если линейные карты пытаются отправить на фабрику больше, чем она способна обработать.
- на выходной линейной карте, если фабрика пытается передать на линейную карту больше, чем её чип способен обработать
- на выходном интерфейсе - если чип шлёт в интерфейс больше, чем тот способен сериализовать.
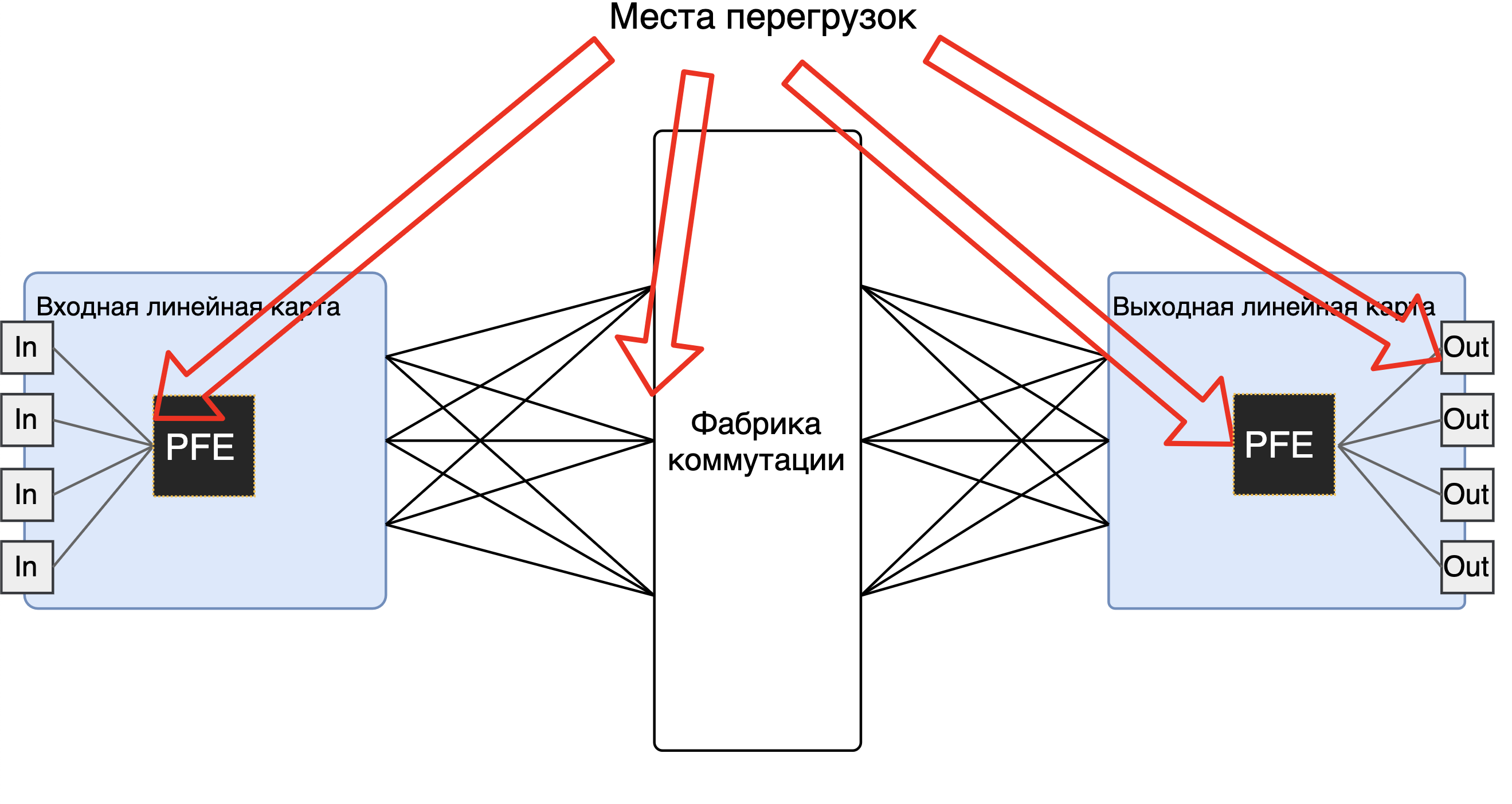
Но никто не хочет бороться с перегрузками в четырёх местах.
Поэтому обычно
А) Чип делают такой производительности, чтобы он смог обработать весь трафик, даже если тот начал одновременно поступать со всех портов на этой линейной карте. Поэтому для устройства со 128 портами 100Гб/с используется чип с производительностью 12,8Тб/с.
Очевидно бывают и исключения. Тогда или имеем непредсказуемые потери, или (чаще) невозможность использовать часть портов.
Б) Фабрику так же делают без переподписки, чтобы она могла провернуть весь трафик, который пытаются в неё передать все линейные карты, даже если они делают это одновременно на полной скорости. Таким образом не нужно буферизировать трафик и перед отправкой на фабрику. Более того, её приходится делать не просто равной сумме пропускных способностей входных/выходных интерфейсов, а больше - там ведь помимо самих пакетов передаются ещё метаданные.
В) Управление перегрузками на выходном чипе и выходном интерфейсе сводят в одно место.
Attention
На самом деле фабрика без передподиски (или неблокируемая) - это та ещё спекуляция, к которой нередко прибегают маркетологи.Для некоторых сценариев, например, CIOQ даже со speedup фабрики в пару раз от необходимого есть строгие результаты, показывающие, при каких условиях она будет неблокируемой.Можно почитать у достопочтенных выпускников MIT и Стэнфорда: On the speedup required for combined input and output queued switching.