Shallow vs Deep Buffers¶
Чуть позже мы поговорим о том, что такое хорошо, а что такое плохо. А пока посмотрим на реализации.
Shallow - неглубокие - это буферы размером до 100МБ. Обычно это встроенная в кристалл on-chip память - OCB - On-Chip Buffer. Deep - счёт уже идёт на гигабайты. Обычно off-chip и подключается к чипу по отдельной шине. И нет ничего посередине.
Такие буферы порой даже называют Extremely shallow buffers.
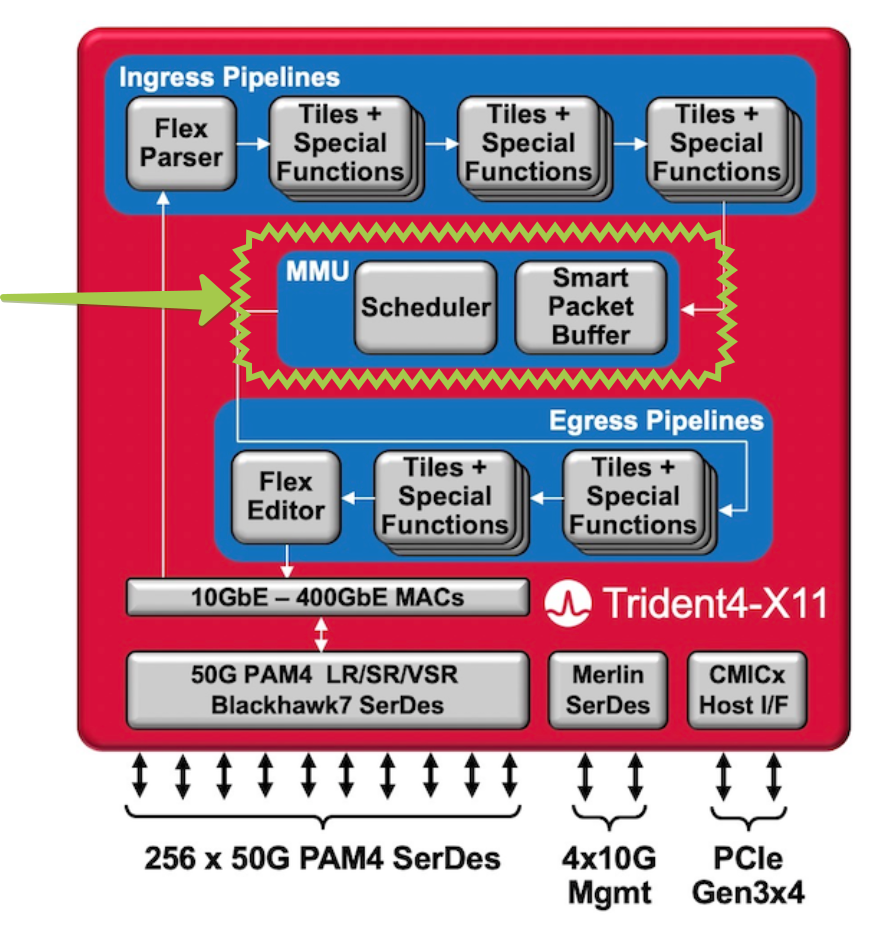
Очевидно, что не для всех задач такие маленькие буферы подходят. В частности модульные коробки с VOQ явно не могут позволить себе дробить 64 Мб на несколько тысяч очередей (на самом деле могут).
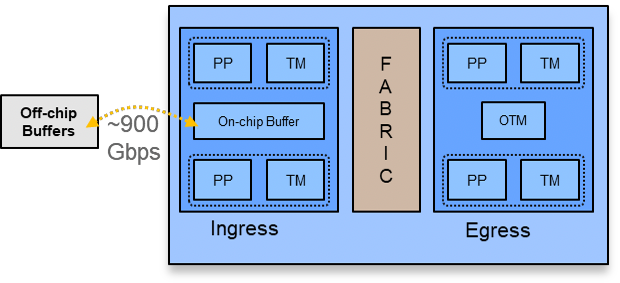
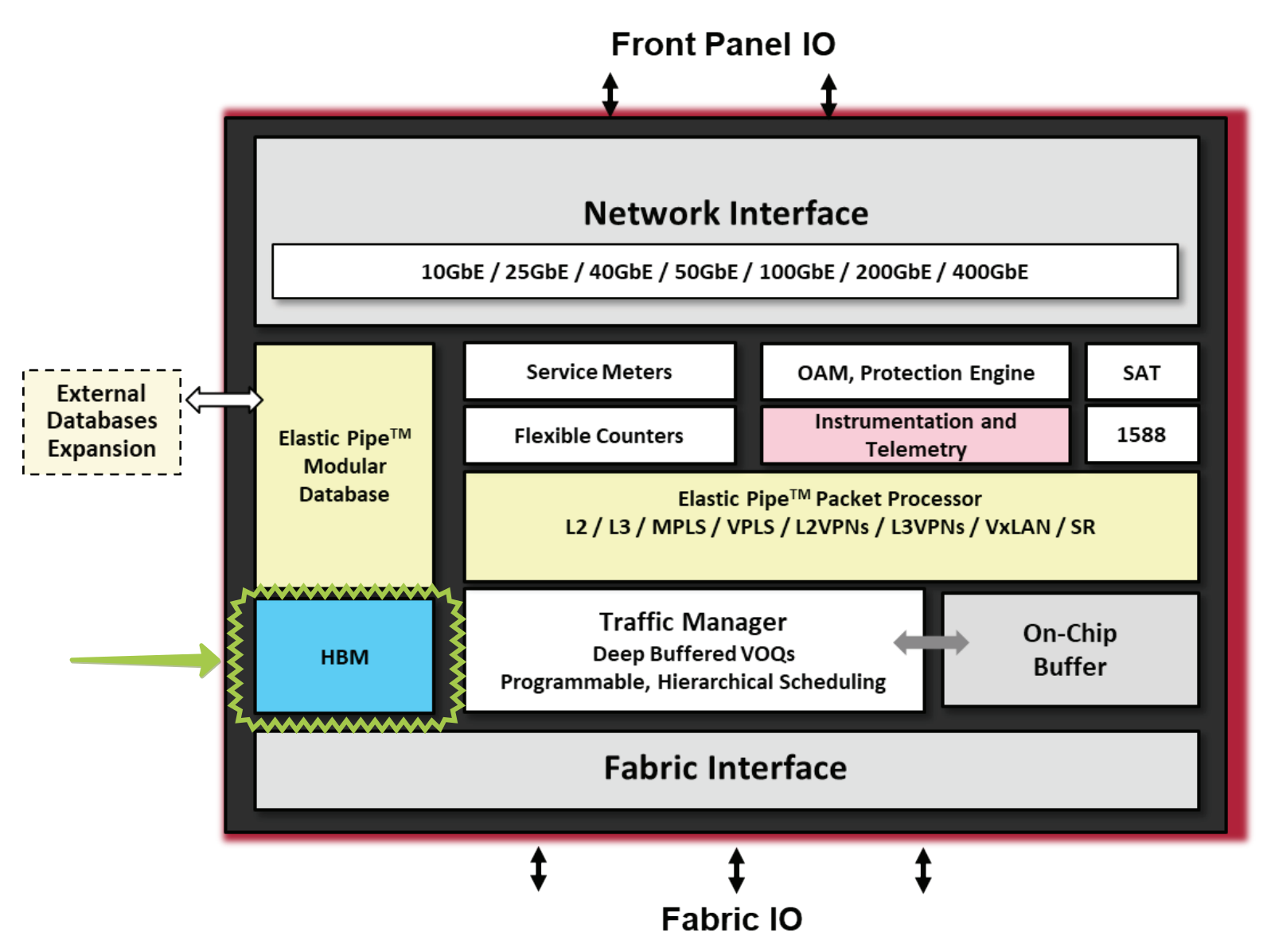
Jericho2 несёт на борту новейшую память HBM2 - High Bandwidth Memory - размером 8ГБ.
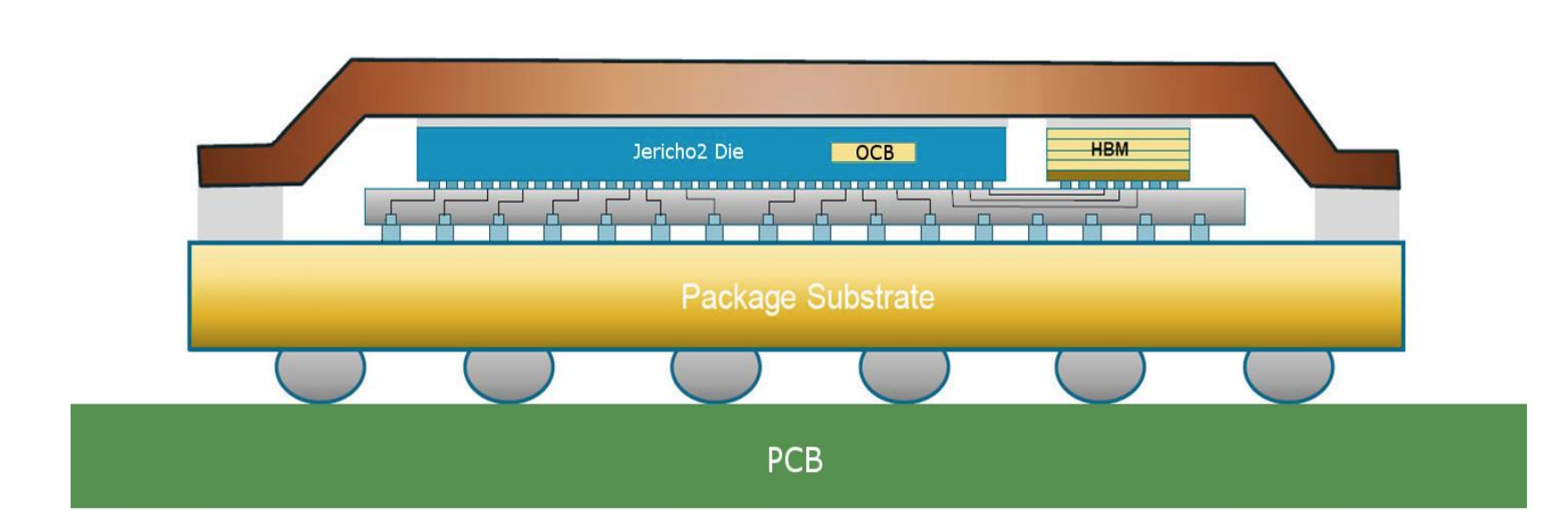
- А вот и фото Jericho2:

Juniper PTX и QFX10000 используют чип Q5 собственного производства с внешней памятью - HMC - Hybrid Memory Cube - в размере 4ГБ.

А вот так выглядит сетевой процессор Cisco с внешней памятью:

Кастомный джуниперовский HMC обещает 1,25 Тб/с в обоих направлениях.
Если верить вики, то HBM 2-го поколения, используемый в последнем чипе Broadcom Jericho2, выдаёт порядка 2Тб/с.
Но это всё ещё далеко от реальной производительности сетевого ASIC. Фактически шины до этой внешней памяти является узким местом, которое и определяет производительность чипа.
Important
Когда-то мир был лучше и было строгое разделение - Shallow Buffer - это встроенная On Chip память, Deep Buffer - внешняя.С развитием WLP ситуация начинает меняться. Память HBM становится co-packaged в один чип вместе с комутационным асиком. TSV и 3D Advanced Packaging значительно увеличивают пропускную способность. И нередко в перезентациях вендорово можно увидеть “Deep Buffer” и “On Chip” в одной фразе.Тут нужно быть осторожным, поскольку шина между асиком и памятью, пусть даже они расположены рядышком на одном интерпозере под общей крышкой, всё ещё является узким местом и ограничивает максимальную пропускную способность.
Hybrid Buffering¶
Поэтому почти все вендоры сегодня практикуют гибридную буферизацию, или, если хотите - динамическую. В нормальных условиях используется только on-chip память, предоставляющая line-rate производительность. А в случае перегрузки пакеты автоматически начинают буферизироваться во внешней памяти. Это позволяет уменьшить стандартные задержки, энергопотребление и в большинстве случаев вписаться в ограниченную полосу пропускания до памяти.
Note
Данный параграф отменяет сказанное выше о том, что on-chip памяти не хватит для VOQ. Фактически в случае гибридной буферизации она всё же дробится на тысячи очередей очень маленькой длины, чтобы обеспечить VOQ. Просто в нормальных условиях этой длины хватает, чтобы пропускать трафик мимо внешней памяти.При этом в первую очередь начнёт офлоадиться на внешнюю память массивный трафик, идущий в низкоприоритетных очередях, а требовательный к задержками будет по-прежнему пролетать фаст-пасом.

Большие буферы - добро или зло?¶
В целом это довольно старая дилемма. Подольше похранить или пораньше дропнуть?
Соответственно на устройствах с глубокими буферами во время заторов пакеты будут долго копиться, не отбрасываясь. Когда они всё-таки дойдут до получателя и тот их ACKнет, отправитель не только не снизит скорость, но может даже её увеличить, если у него сейчас режим Slow Start или Congestion Avoidance.
Можно взглянуть и дальше: растущая очередь взвинчивает RTT, что соответственно влечёт за собой увеличение RTO таймеров на отправителях, тем самым замедляя обнаружение потерь.
Проект www.bufferbloat.net иронично определил этот термин, как «ухудшение производительности Интернета, вызванное предыдущими попытками её улучшения»
Отбросы - санитары сети. Ко всеобщему удивлению, уменьшение очереди до одного пакета зачастую может кардинально улучшить ситуацию, особенно в условиях датацентра (только не сочтите это за дельный совет).
Note
Справедливости ради следует заметить, что современные реализации TCP - BBR2, TIMELY ориентируются не только и не столько на потери, сколько на RTT и BDP.Гугловый QUIC - надстройку над UDP - следует отнести сюда же.
Итак, устройства с большим объёмом памяти годятся в места где заложена переподписка или могут появиться заторы.
Storage. Это штука крайне чувствительная к потерям и тоже гоняющая массивные объёмы данных. В случае хранилки тоже лучше не терять ничего. Но обычно она при этом и к задержкам предъявляет строгие требования, поэтому такие приложения обсудим пониже.
Однако при этом крайне редко они единственные потребители сети в датацентрах, другим приложениям нужна низкая задержка.
Впрочем, это легко решается выделением очередей QoS с ограничением максимальной доступной глубины. И весь вопрос заключается тогда только в том, готова ли компания заплатить за глубокие буферы, возможно, не использовать их и поддерживать конфигурацию QoS.
Но в любой ситуации лучше следовать правилу: use shallow ASIC buffers when you can and use deep buffers when you must.
Критика глубоких буферов:
Кстати, показательная таблица типичных задержек:
