Архитектура буферов¶
И вот тут на сцену выходит TM - Traffic Manager, который реализует функции QoS (и некоторые другие). Он может быть частью чипа коммутации, а может быть отдельной микросхемой - для нас сейчас важно то, что он заправляет буферами.
Буфер - это с некоторыми оговорками обычная память, используемая в компьютерах. В ней в определённой ячейке хранится пакет, который чип может извлечь, обратившись по адресу.
Любой сетевой ASIC или NP обладает некоторым объёмом встроенной (on-chip) памяти (порядка десятков МБ). Так называемые Deep-Buffer свитчи имеют ещё внешнюю (off-chip) память, исчисляемую уже гигабайтами. И той и другой управляет модуль чипа - MMU.
В целом для нас пока местонахождение не имеет значения - взглянем на это попозже. Важно то, как имеющейся памятью чип распоряжается, а именно, где и какие очереди он создаёт и какие AQM использует.
И тут практикуют:
Crossbar¶
Идея в том, чтобы для каждой пары (входной интерфейс - выходной интерфейс) выделить аппаратный буфер.
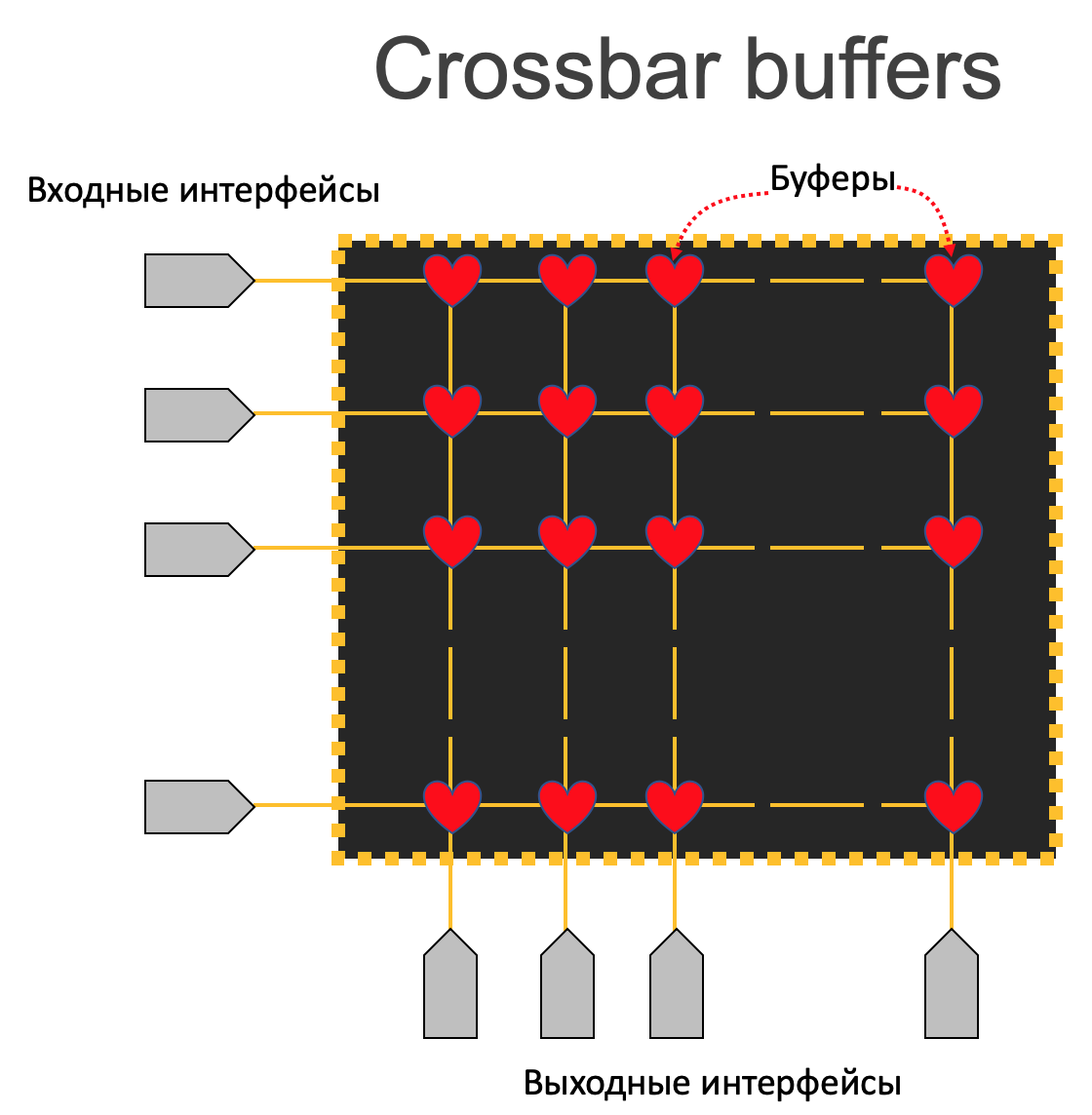
Это, скорее, умозрительный эксперимент, потому что в плане сложности, стоимости реализации и эффективности это проигрышный вариант.
Shared Buffer¶
По числу существующих в мире коробок этот вариант, однозначно, на первом месте.
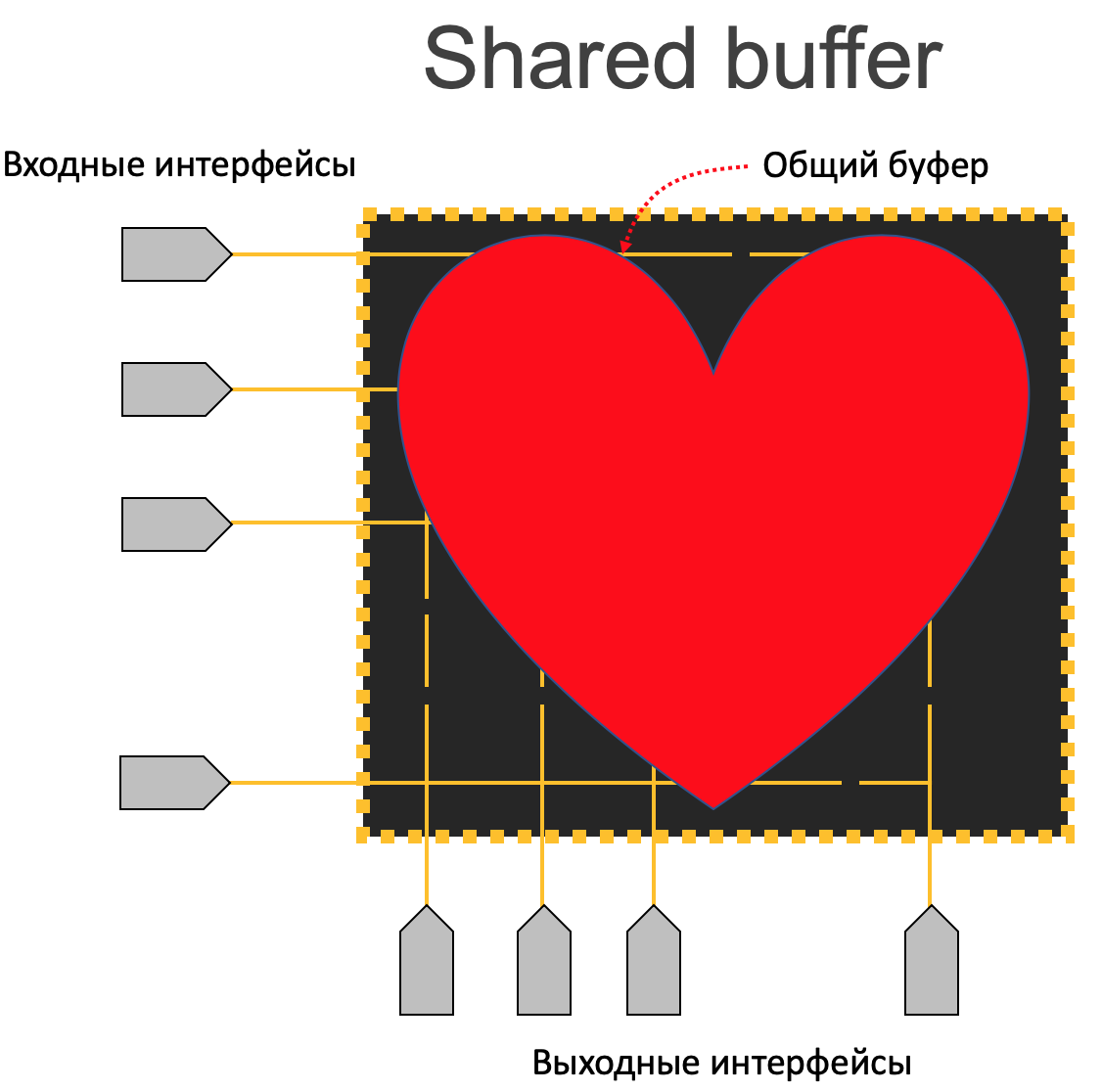
Используется Shared Buffer на немодульных устройствах без фабрики коммутации, в которых установлен один чип (обычно, но может быть больше).
Итак, есть соблазн эту память взять и просто равномерно разделить между всеми портами. Такой статический дизайн имеет право на жизнь, но сводит на нет возможность динамически абсорбировать всплески трафика.
Гораздо более привлекательным выглядит следующий вариант:
Headroom buffers¶
Помимо lossless headroom бывает и headroom для обычного трафика, чтобы помочь сохранить более приоритетный. Но это на домашнее задание.
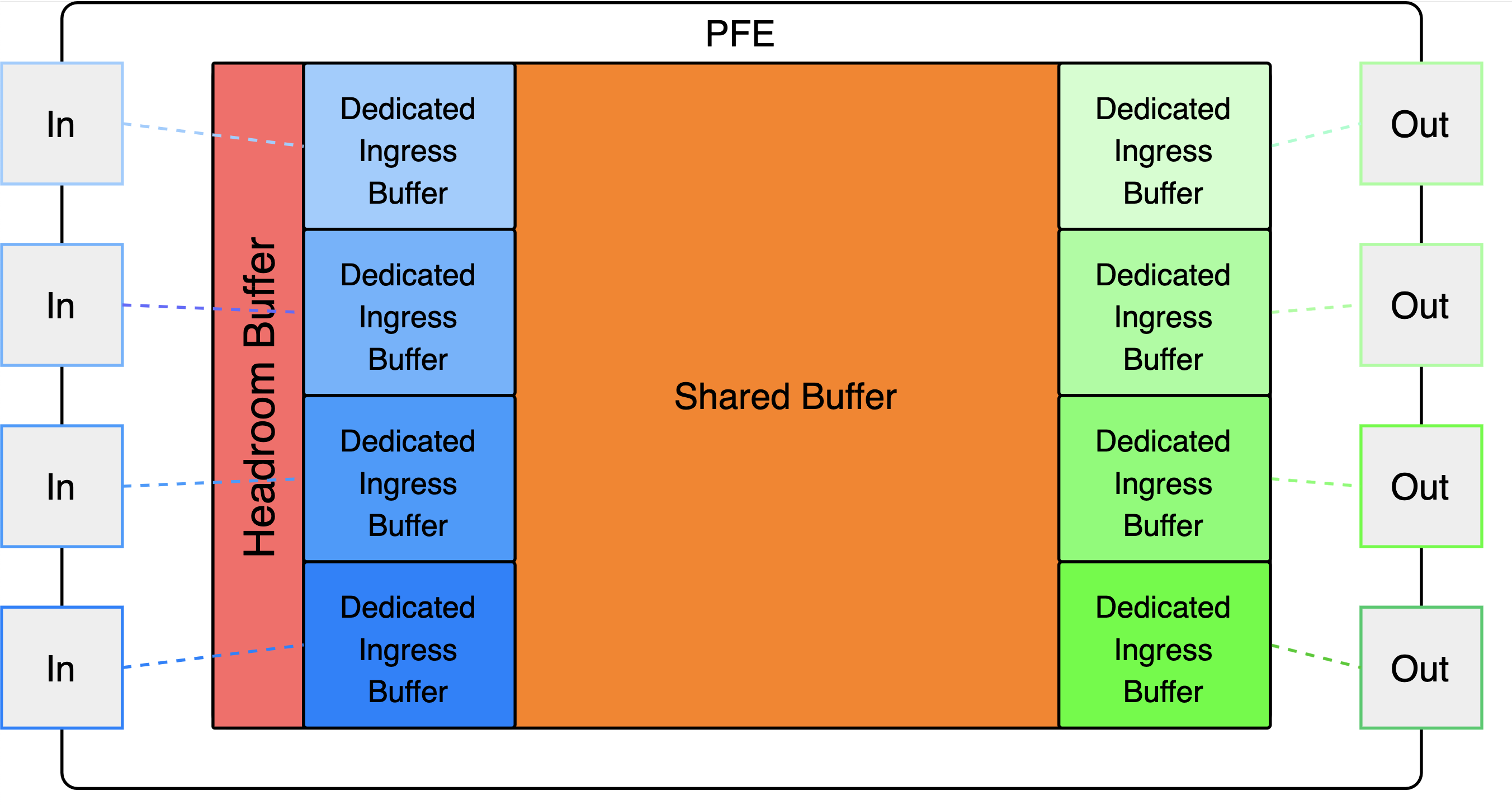
- Dedicated buffers
- Shared buffers
Для входящего lossless трафика:
- Dedicated buffers
- Shared buffers
- Lossless headroom buffers
Для всего исходящего трафика:
- Dedicated buffers
- Shared buffers
Разумеется, описанное выше лишь частный пример, и от вендора к вендору ситуация может различаться (разительно).
Например бродкомовские чипы (как минимум Trident и Tomahawk) имеют внутреннее разделение памяти по группам портов. Общая память делится на порт-группы по 4-8 портов, которые имеют свой собственный кусочек общего буфера. Порты из одной группы, соответственно буферизируют пакеты только в своём кусочке памяти и не могут занимать другие. Это тоже один из способов снизить влияние перегруженных портов друг на друга. Такой подход иногда называют Segregated Buffer.
Admission Control¶
Admission Control - входной контроль - механизм, который следит за тем, можно ли пакет записывать в буфер. Он не является специфичным для Shared-буферов, просто в рамках статьи - это лучшее место, чтобы о нём рассказать.
Задача Egress Admission Control - помочь чипу абсорбировать всплески, не допустив того, чтобы один или несколько выходных портов забили целиком весь буфер, получая всё новые и новые пакеты с кучи входных портов.
В случае Shared Buffer оба механизма срабатывают в момент первичного помещения пакета в буфер. То есть никакой двойной буферизации и проверки не происходит.
Alpha¶
Итак, почти во всех современных чипах память распределяется динамически на основе информации о том, сколько общей памяти вообще свободно и сколько ещё можно выделить для данного порта/очереди.
На самом деле минимальной единицей аккаунтинга является не порт/очередь, а регион (в терминологии Мелланокс). Регион - это кортеж: (входной порт, Priority Group на входном порту, выходной порт, Traffic Class на выходном порту).
Threshold [Bytes] = alpha * free_buffer [Bytes]
Предполагаем тут, что значение alpha одинаково для всех регионов, хотя оно может быть настроено отдельно для каждого.
Написанное выше об Admission Control и Alpha может быть справедливо не только для Shared Buffers, но и для других архитектур, например, VoQ.
Дальнейшее чтиво:
- Если в жизни не хватает страданий: Design and Implementation of a Shared Memory Switch Fabric
- Understanding the Alpha Parameter in the Buffer Configuration of Mellanox Spectrum Switches
- Programming Guide’ы коммерческих микросхем (NDA кровью, помним, да?).

Далее поговорим про архитектуры памяти для модульных шасси.
Output Queueing¶


Input Queuing¶
Более удачным вариантом оказывается буферизировать пакеты на входной плате после лукапа, когда уже становится понятно, куда пакет слать. Если выходной интерфейс заведомо занят, то и смысла гнать камикадзе на фабрику нет.
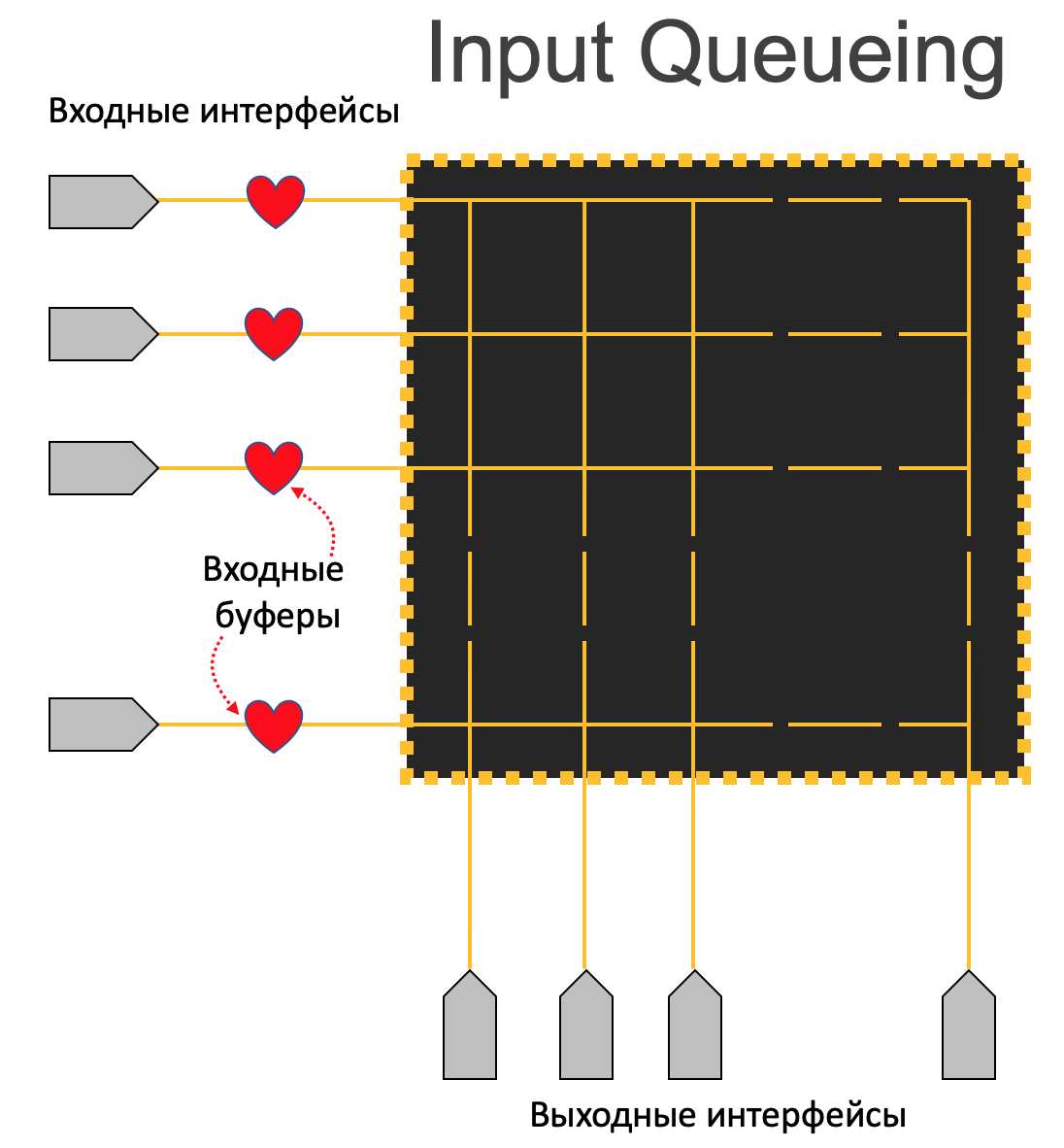
Постойте! Как же входной чип узнает, что выходной интерфейс не занят?
Combined Input and Output Queueing¶
Гораздо выгоднее в этом плане разрешить буферизацию и на выходе. Тогда арбитр будет проверять не занятость интерфейса, а степень заполненности выходного буфера - вероятность, что в нём есть место, гораздо выше.
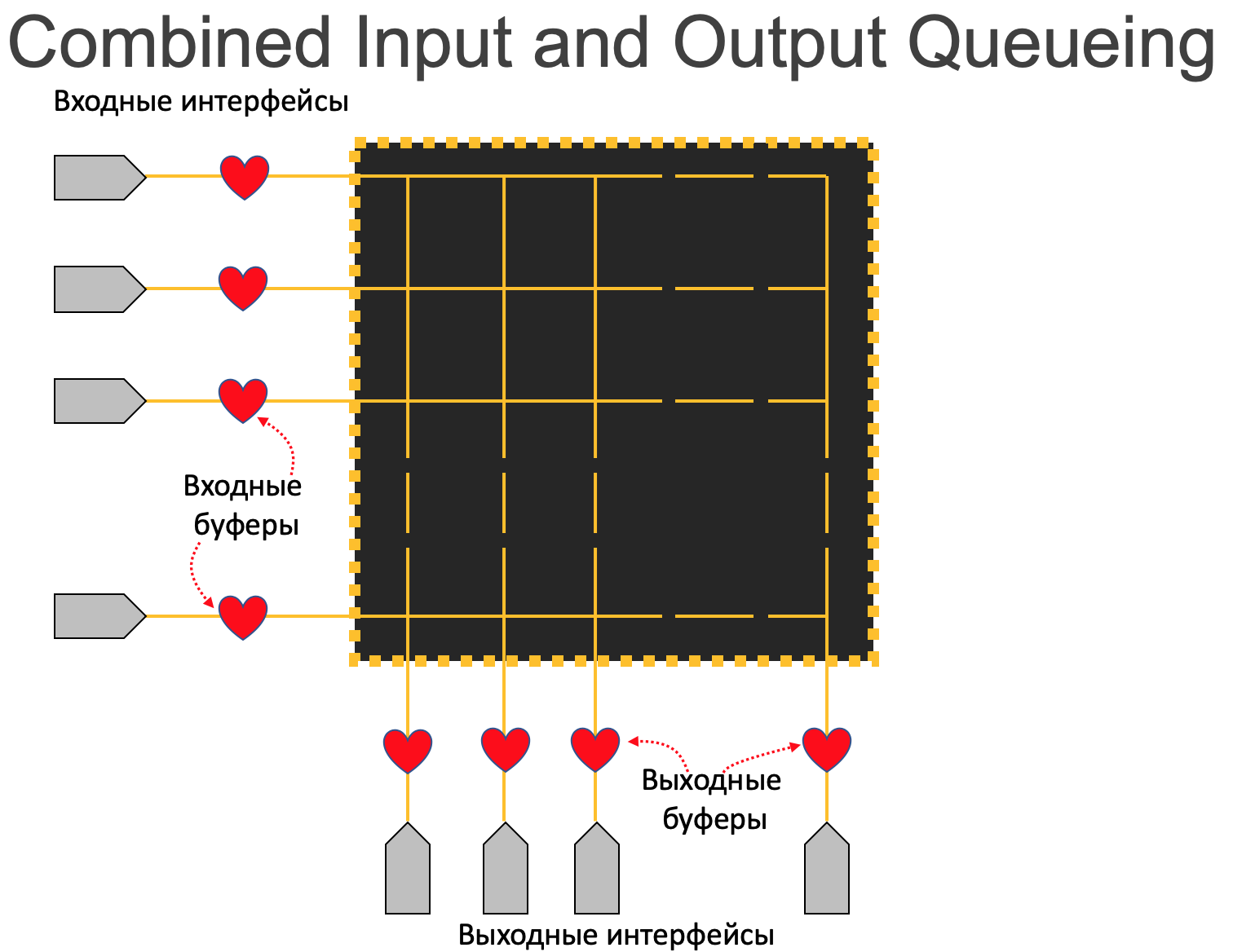
Но такие вещи не даются даром. Очевидно, это и увеличенная цена из-за необходимости реализовывать дважды буферизацию, и увеличенные задержки - даже в отсутствие заторов этот процесс не бесплатный по времени.
Кроме того, для обеспечения QoS придётся хоть какой-то минимум его функций реализовывать в двух местах, что опять же скажется на цене продукта
Но у CIOQ (как и у IQ) есть фундаментальный недостаток, заставивший в своё время немало поломать голову лучшим умам - Head of Line Blocking.
Представьте себе ситуацию: однополосная дорога, перекрёсток, машине нужно повернуть налево, сквозь встречный поток. Она останавливается, и ждёт, когда появится окно для поворота. А за ней стоит 17 машин, которым нужно проехать прямо. Им не мешает встречный поток, но им мешает машина, которая хочет повернуть налево.
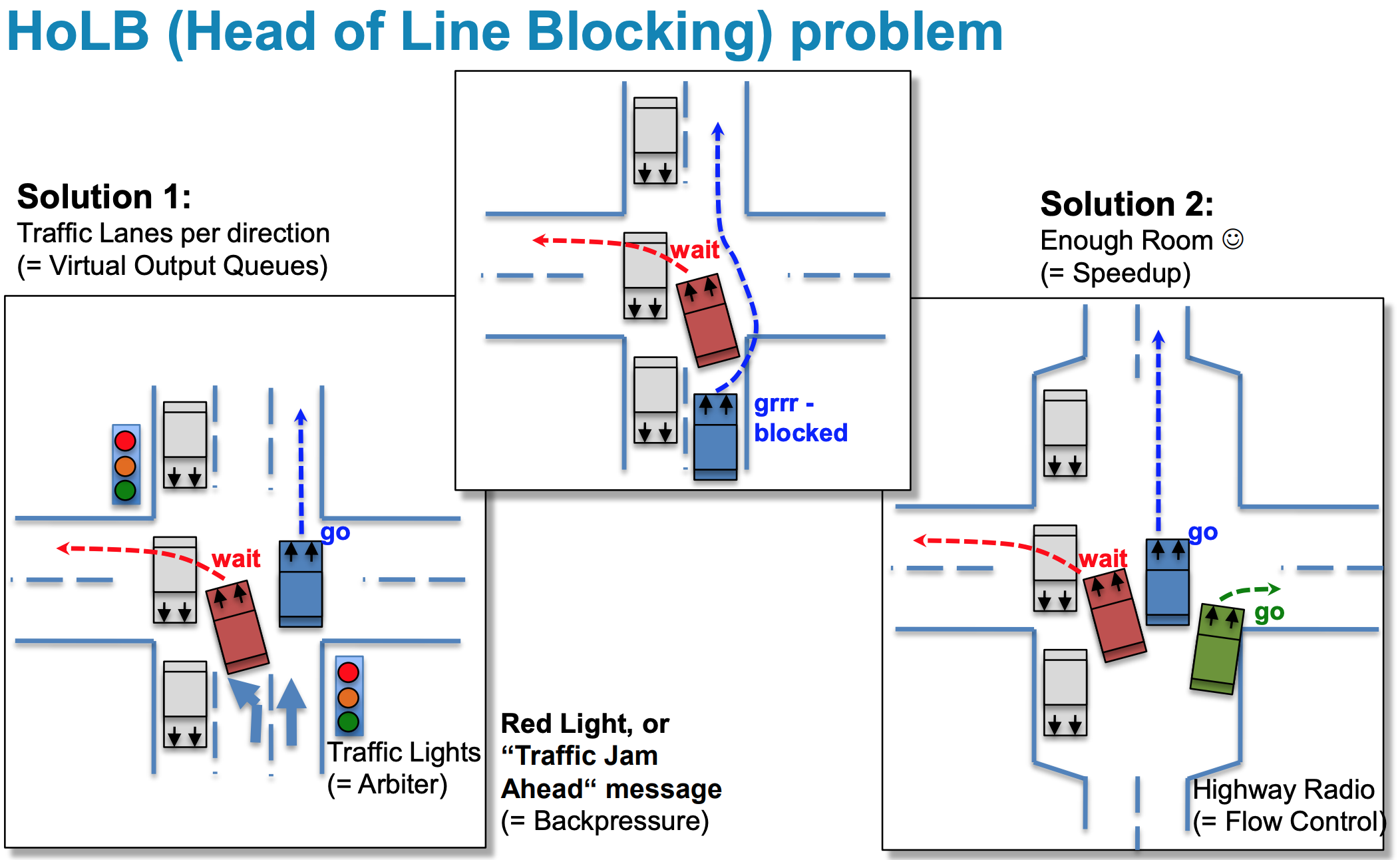
Этот избитый пример иллюстрирует ситуацию HoLB. Входной буфер - один на всех. И если всего лишь один выходной интерфейс начинает испытывать затор, он блокирует полностью очередь отправки на выходном чипе, поскольку один пакет в начале этой очереди не получает разрешение на отправку на фабрику.
Трагическая история, как в реальной жизни, так и на сетевом оборудовании.
Virtual Output Queueing¶
Как можно исправить эту дорожную ситуацию? Например, сделав три полосы - одна налево, другая прямо, третья направо.
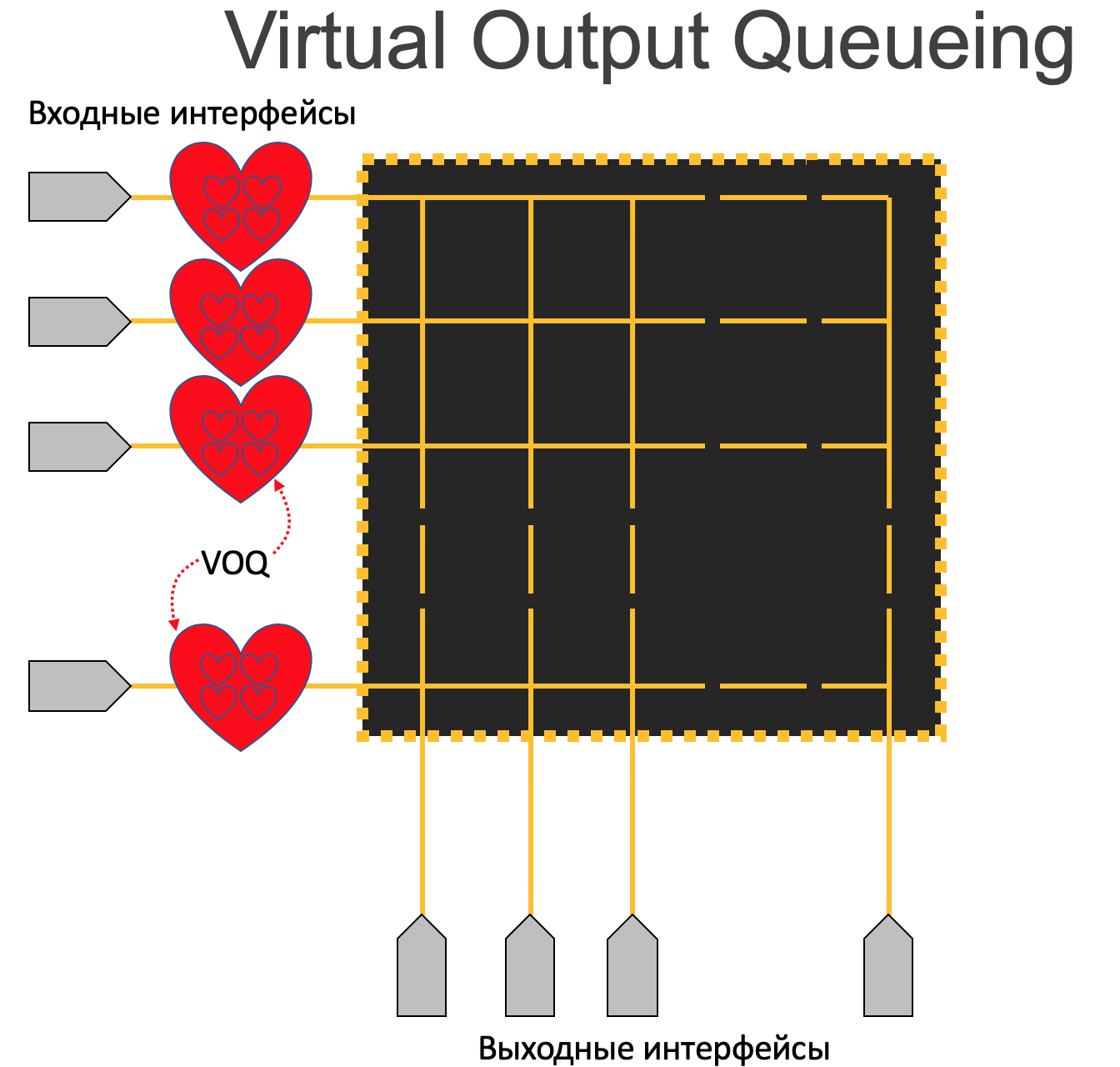
Кстати, что касается трафика, который должен вернуться в интерфейс той же карты, на которую он пришёл изначально, то здесь никаких исключений - он томится в VOQ, пока чип не даст добро переложить его в выходную очередь. С тем только отличием, что пакет не будет отправляться на фабрику. Поэтому перед лицом перегрузок все равны.
Combined Input and Output Queueing w/ Virtual Output Queueing¶
Как сделать еще сложнее? Совместить обе вышепреведённые техники буферизации. VoQ применяется на фабрике, то есть только для виртуальных портов подключающих Switch Fabric к Egress Line Card NPU, таких портов в сторону NPU относительно немного и виртуальная очередь (VoQ) всё так же находится на Ingress Line Card.
Таким образом у каждого Ingress NPU есть виртуальные очереди для каждого из Egress NPU, таких очередей может быть несколько.
После того как трафик прошёл через фабрику минуя fabric VoQ, пакет в любом случае попадёт в очередь на исходящем интерфейсе (Egress Interface Output Queue) и или задержится там если в данный момент интерфейс перегружен, или сбросится если очередь заполнена полностью, или отправится дальше в исходящий интерфейс.
Данная техника не подвержена HoLB эффекту в той же мере что и классическая CIOQ, однако в случае когда трафик идёт на два разных исходящих интерфейса за одним NPU в случае затора на порту фабрики проблема HoLB всё таки может присутствовать.
CIOQ w/ VoQ fabric масштабируется гораздо лучше чем E2E VoQ из-за меньшего количества интерфейсов, а следовательно и очередей, поэтому подходит для PE, BNG и другого оборудования с большим количеством интерфейсов. Однако, недостаток двойной буферизации никуда не делся, как и недостаток размещения памяти в двух местах и как следствие бОльшего потребления энергии.
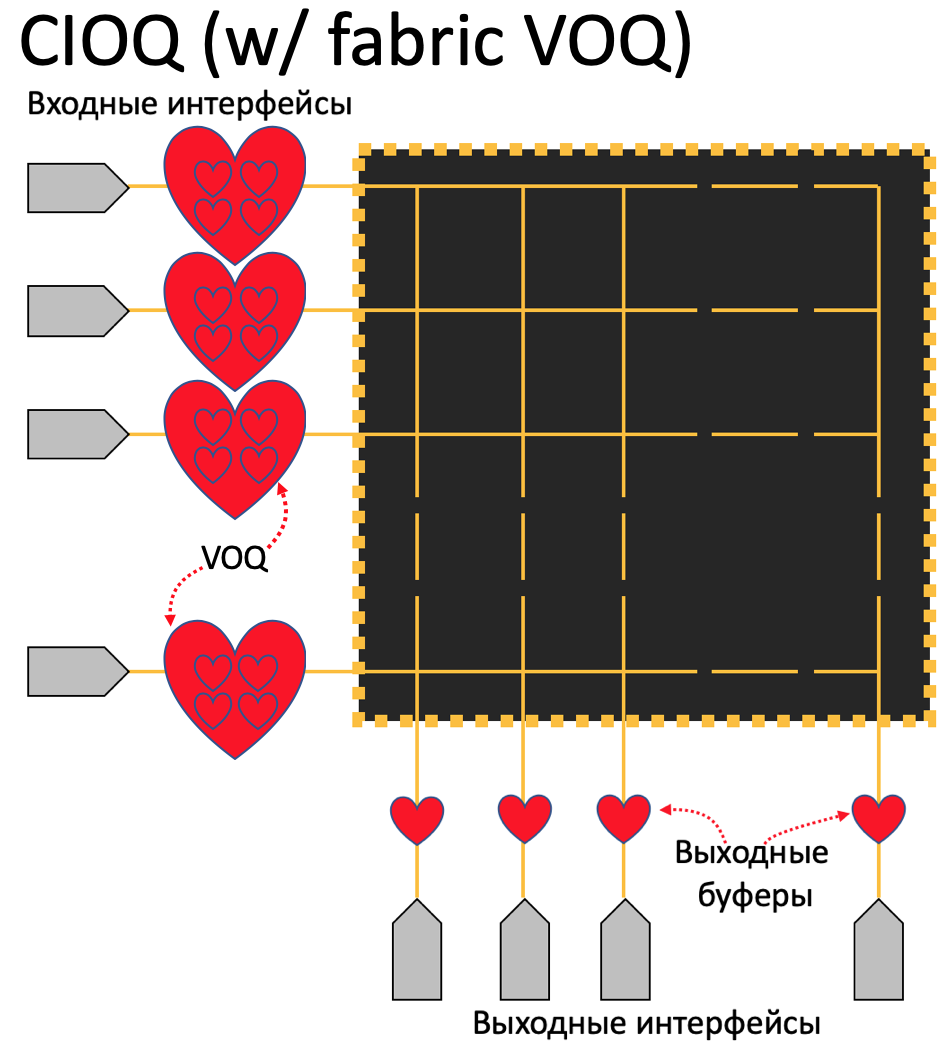
На сегодняшний день End-to-End VOQ является наиболее прогрессивной технологией, но говорить о её безоговорочной победе пока не приходится. Картинка с NANOG65 (2015):
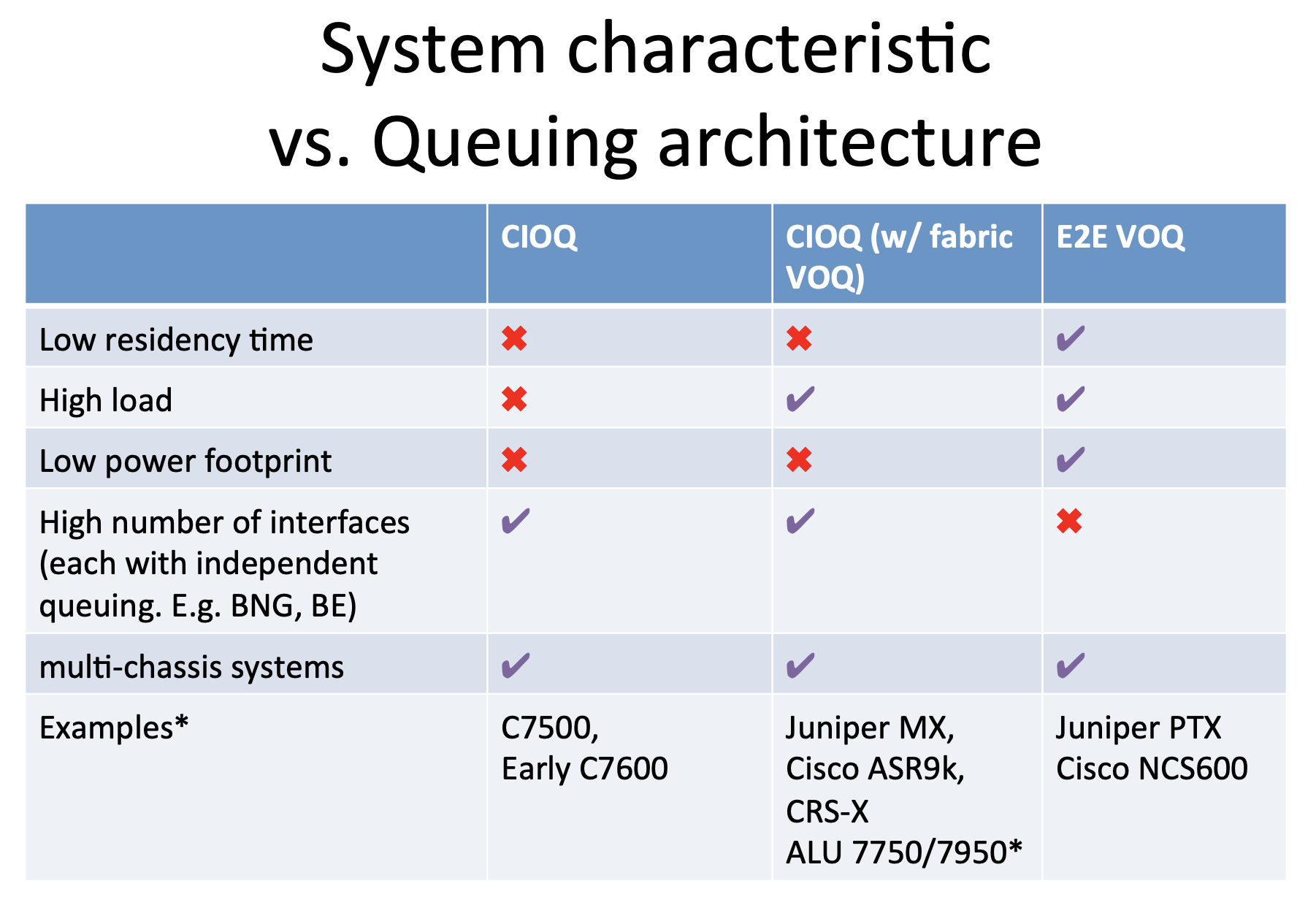
Дальнейшее чтиво: